import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import causalpy as cp
Inverse Propensity Score Weighting with pymc#
In this notebook we will briefly demonstrate how to use propensity score weighting schemes to recover treatment effects in the analysis of observational data. We will first showcase the method with a simulated data example drawn from Lucy D’Agostino McGowan’s excellent blog on inverse propensity score weighting. Then we shall apply the same techniques to NHEFS data set discussed in Miguel Hernan and Robins’ Causal Inference: What if book. This data set measures the effect of quitting smoking between the period of 1971 and 1982. At each of these two points in time the participant’s weight was recorded, and we seek to estimate the effect of quitting in the intervening years on the weight recorded in 1982.
We will use inverse propensity score weighting techniques to estimate the average treatment effect. There are a range of weighting techniques available: we have implemented raw, robust, doubly robust and overlap weighting schemes all of which aim to estimate the average treatment effect. The idea of a propensity score (very broadly) is to derive a one-number summary of individual’s probability of adopting a particular treatment. This score is typically calculated by fitting a predictive logit model on all an individual’s observed attributes predicting whether or not the those attributes drive the individual towards the treatment status. In the case of the NHEFS data we want a model to measure the propensity for each individual to quit smoking.
🎯 Target Causal Estimands
Propensity score weighting allows us to estimate different causal effects by changing the “target population” we are interested in. The choice of weight determines which estimand you are calculating:
ATE (Average Treatment Effect): Estimates the effect if the entire population were treated vs. the entire population being untreated. Targeted by the
make_raw_adjustmentsandmake_robust_adjustmentsmethods.ATO (Average Treatment Effect among the Overlap): Targeted by
make_overlap_adjustments. This focuses on units with “clinical equipoise”—those who had a reasonable probability of being in either group. It is highly robust to outliers and eliminates the need for artificial clipping.Doubly Robust: The
make_doubly_robust_adjustmentcombines a propensity model and an outcome model. It targets the ATE but provides “two chances” to be correct: if either the propensity model or the outcome model is correctly specified, the estimate remains unbiased.
The reason we want this propensity score is because with observed data we often have a kind of imbalance in our covariate profiles across treatment groups. Meaning our data might be unrepresentative in some crucial aspect. This prevents us cleanly reading off treatment effects by looking at simple group differences. These “imbalances” can be driven by selection effects into the treatment status so that if we want to estimate the average treatment effect in the population as a whole we need to be wary that our sample might not give us generalisable insight into the treatment differences. Using propensity scores as a measure of the prevalance to adopt the treatment status in the population, we can cleverly weight the observed data to privilege observations of “rare” occurrence in each group. For example, if smoking is the treatment status and regular running is generally not common among the group of smokers, then on the occasion we see a smoker marathon runner we should heavily weight their outcome measure to overcome their low prevalence in the treated group but real presence in the unmeasured population. Inverse propensity weighting tries to define weighting schemes are inversely proportional to an individual’s propensity score so as to better recover an estimate which mitigates (somewhat) the risk of selection effect bias. For more details and illustration of these themes see the PyMC examples write up on Non-Parametric Bayesian methods. [Forde, 2024]
Simulated Data#
First we simulate some data for treatment and outcome variables.
df1 = pd.DataFrame(
np.random.multivariate_normal([0.5, 1], [[2, 1], [1, 1]], size=1000),
columns=["x1", "x2"],
)
df1["trt"] = np.where(
-0.5 + 0.25 * df1["x1"] + 0.75 * df1["x2"] + np.random.normal(0, 1, size=1000) > 0,
1,
0,
)
TREATMENT_EFFECT = 2
df1["outcome"] = (
TREATMENT_EFFECT * df1["trt"]
+ df1["x1"]
+ df1["x2"]
+ np.random.normal(0, 1, size=1000)
)
df1.head()
| x1 | x2 | trt | outcome | |
|---|---|---|---|---|
| 0 | 2.002264 | 2.064894 | 1 | 6.771880 |
| 1 | 0.159616 | 2.634011 | 1 | 5.197324 |
| 2 | 3.734532 | 2.202380 | 1 | 6.897097 |
| 3 | -1.817222 | -0.581287 | 0 | -3.478222 |
| 4 | 0.712104 | 0.796235 | 1 | 5.279414 |
Note how we have specified the treatment effect of interest to be exactly 2.
Now we invoke the InversePropensityWeighting experiment class, with the PropensityScore model. This will by default fit a simple logistic regression model and store the idata under result1.idata.
seed = 42
result1 = cp.InversePropensityWeighting(
df1,
formula="trt ~ 1 + x1 + x2",
outcome_variable="outcome",
weighting_scheme="robust",
model=cp.pymc_models.PropensityScore(
sample_kwargs={
"draws": 1000,
"target_accept": 0.95,
"random_seed": seed,
"progressbar": False,
},
),
)
result1
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [b]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
Sampling: [b, t_pred]
Sampling: [t_pred]
<causalpy.experiments.inverse_propensity_weighting.InversePropensityWeighting at 0x13b82e900>
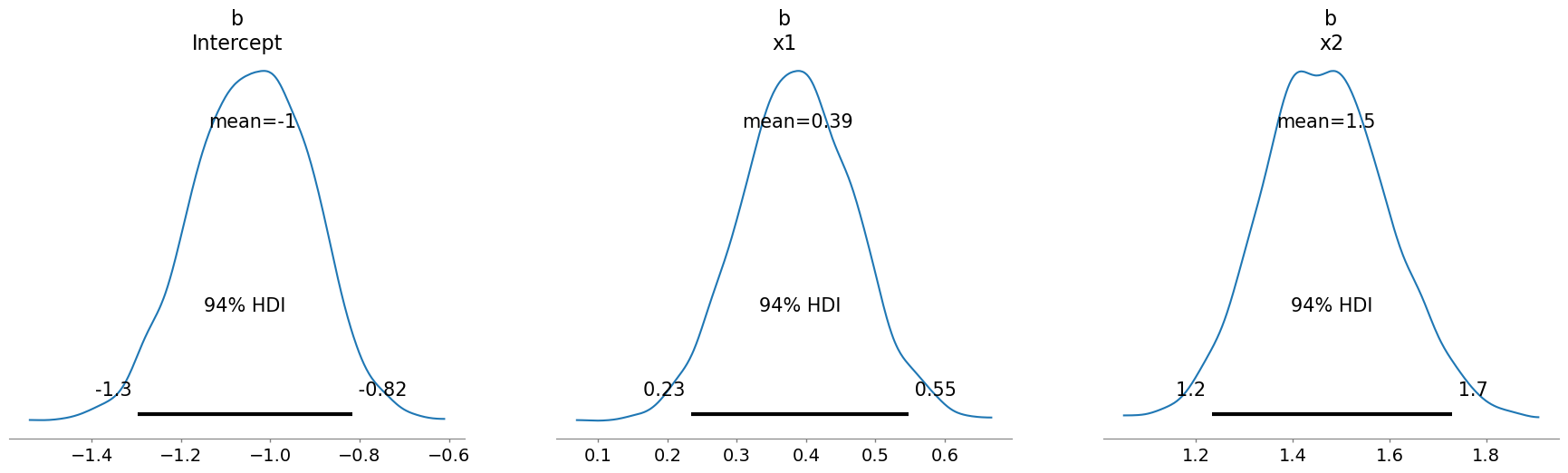
We can interrogate this inference data object in the usual fashion to assess the model fit of the propensity score model. Looking here at the parameters in the logistic regression.
az.plot_posterior(result1.idata, var_names=["b"]);
The health of the sampling trace.
az.plot_trace(result1.idata, var_names=["b"]);
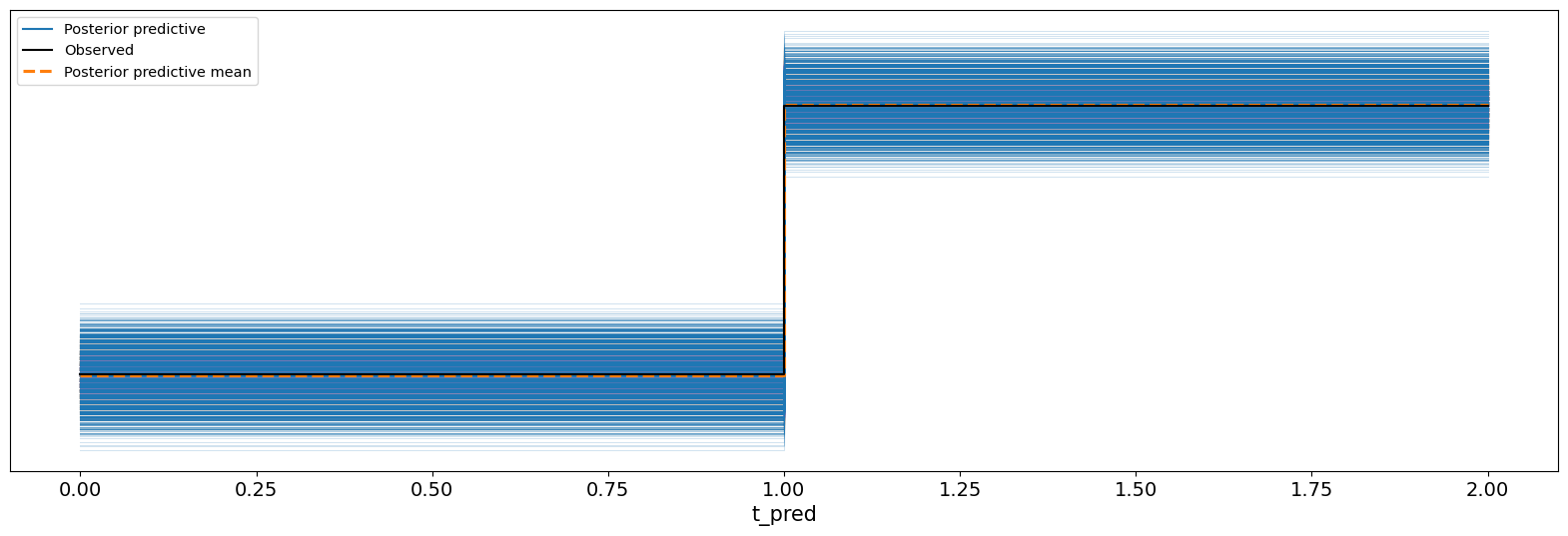
The posterior predictive checks of our propensity model show the predicted binary outcomes (i.e. smoker yes/no) drawn from the posterior predictive distribution in blue. This is contrasted against the observed outcomes in our data set in black. In short this plot shows how the model is able to recover the observed data.
fig, ax = plt.subplots(figsize=(20, 6))
az.plot_ppc(result1.idata, ax=ax);
But our primary focus when we’re conducting an inverse propensity weighting experiment is not on the accuracy of the propensity score model itself. Instead we want to incorporate these propensity scores latent in the logistic regression to re-weight the outcomes of interest to have a better, more representative measure of the treatment mitigating some of the risk of selection effects driving the data generating function.
result1.idata["posterior"]["p"].mean(dim=("chain", "draw"))
<xarray.DataArray 'p' (p_dim_0: 1000)> Size: 8kB
array([0.94013521, 0.94587806, 0.97357412, 0.07047424, 0.59962734,
0.39153459, 0.22843138, 0.17514229, 0.98243388, 0.59513438,
0.51082978, 0.52970017, 0.98829393, 0.84794037, 0.80150665,
0.22657399, 0.87094108, 0.05827419, 0.6944362 , 0.879333 ,
0.70107777, 0.51317638, 0.7752924 , 0.7169492 , 0.9351884 ,
0.37127509, 0.10694603, 0.71281327, 0.80532013, 0.06504384,
0.47650617, 0.11319236, 0.94368536, 0.88710344, 0.73149672,
0.20820406, 0.05143633, 0.13003477, 0.82884517, 0.75873588,
0.73246446, 0.75677087, 0.8305393 , 0.42662905, 0.81625381,
0.98155595, 0.95211544, 0.70280975, 0.86867857, 0.87431244,
0.6930373 , 0.61715956, 0.17561929, 0.8973847 , 0.24501695,
0.38993888, 0.635109 , 0.75790817, 0.25486594, 0.93095542,
0.97857279, 0.10209207, 0.91408255, 0.42143141, 0.47152766,
0.40987547, 0.7370019 , 0.56337666, 0.49040481, 0.51121703,
0.26024819, 0.55952446, 0.97352894, 0.92751331, 0.87849189,
0.64625667, 0.79160682, 0.76723748, 0.99148244, 0.78172117,
0.71755096, 0.95106548, 0.10204632, 0.95560638, 0.76646605,
0.83964007, 0.14602708, 0.94556451, 0.88440252, 0.17341665,
0.0886067 , 0.82501456, 0.41446534, 0.12305624, 0.1344002 ,
0.7084856 , 0.07847229, 0.91657533, 0.8333751 , 0.63687469,
...
0.26693949, 0.55852606, 0.56724051, 0.97704844, 0.40569052,
0.20720328, 0.95007136, 0.80408047, 0.12964485, 0.90799098,
0.6449522 , 0.90613553, 0.95494491, 0.71428852, 0.62855445,
0.37743464, 0.22687608, 0.69184156, 0.99252702, 0.69041483,
0.90633509, 0.5092631 , 0.85067532, 0.82714989, 0.67897361,
0.51510072, 0.84160391, 0.9626245 , 0.20476756, 0.9471935 ,
0.11568715, 0.77143882, 0.17781067, 0.11445909, 0.55398993,
0.41845085, 0.92928379, 0.86825049, 0.93563719, 0.98533913,
0.61408154, 0.17904279, 0.40611243, 0.54351208, 0.18401415,
0.23149838, 0.4251588 , 0.95872535, 0.68629741, 0.91304586,
0.99576352, 0.60031964, 0.84279947, 0.87845774, 0.1777686 ,
0.96402257, 0.34286543, 0.8720219 , 0.66825117, 0.91332038,
0.14929245, 0.32066193, 0.38971751, 0.92705867, 0.66562746,
0.61512078, 0.03391805, 0.23799228, 0.22889447, 0.19000668,
0.54973554, 0.06284224, 0.81841128, 0.08257113, 0.59961309,
0.57934342, 0.21642361, 0.83947054, 0.97208653, 0.24160347,
0.49356149, 0.811892 , 0.47981829, 0.9562438 , 0.1572053 ,
0.77688802, 0.2623462 , 0.60374797, 0.92601078, 0.0827922 ,
0.18125772, 0.84765485, 0.98209249, 0.58541456, 0.87854973,
0.98282276, 0.52932956, 0.15974765, 0.51324628, 0.7855942 ])
Coordinates:
* p_dim_0 (p_dim_0) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999It is these propensity scores which we will use to determine how to weigh the contribution of each individual in our sample when calculating the causal contrast of interest.
Evaluating Balance#
One of the main criteria for success with the estimation of propensity scores is to check how balanced the covariate profiles of our data are across the treatment status under different re-weighting schemes. A good balance of the covariate values across the treatment status is suggestive of the requirement that assignment to a treatment status should be as good as random when conditional on the covariate profile \(X\). That is to say, the condition of strong ignorability holds when the treatment status \(T\) is independent of the propensity \(p(X)\) conditional on \(X\).
One visual way to analyse this balance is to look at the empirical cumulative distribution function for each covariate conditional on the different realisation of propensity scores under the different weighting schemes. We can contrast the difference in the shapes of the ECDFs using the following function.
result1.plot_balance_ecdf("x1", weighting_scheme="raw");
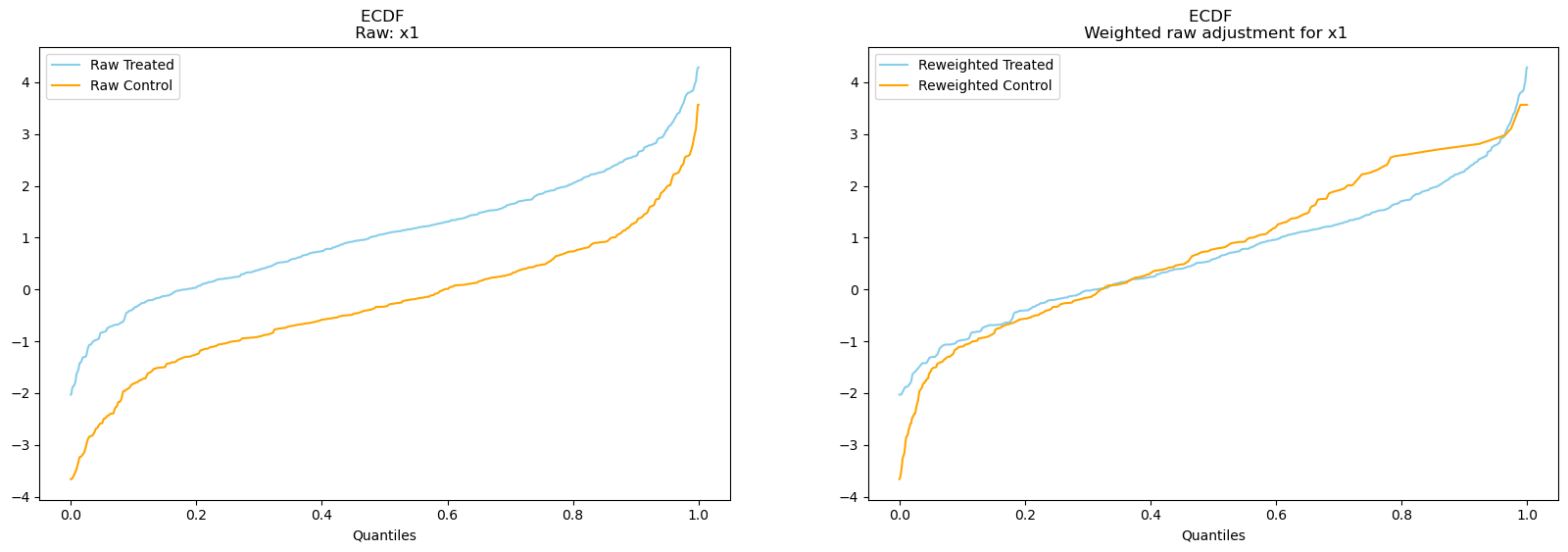
On the left we see the unweighted ECDF of the x1 variable for both treatment and control groups. On the right we show the same but have used weigting to better align the two ECDF profiles. Note here how the re-weighting of the variable using the raw scheme has served to align the shapes of the distribution among both treatment groups, apart from a slight gap at the upper quantiles of the re-weighted ECDF. What happens if we use a different weighting scheme?
result1.plot_balance_ecdf("x1", weighting_scheme="overlap");
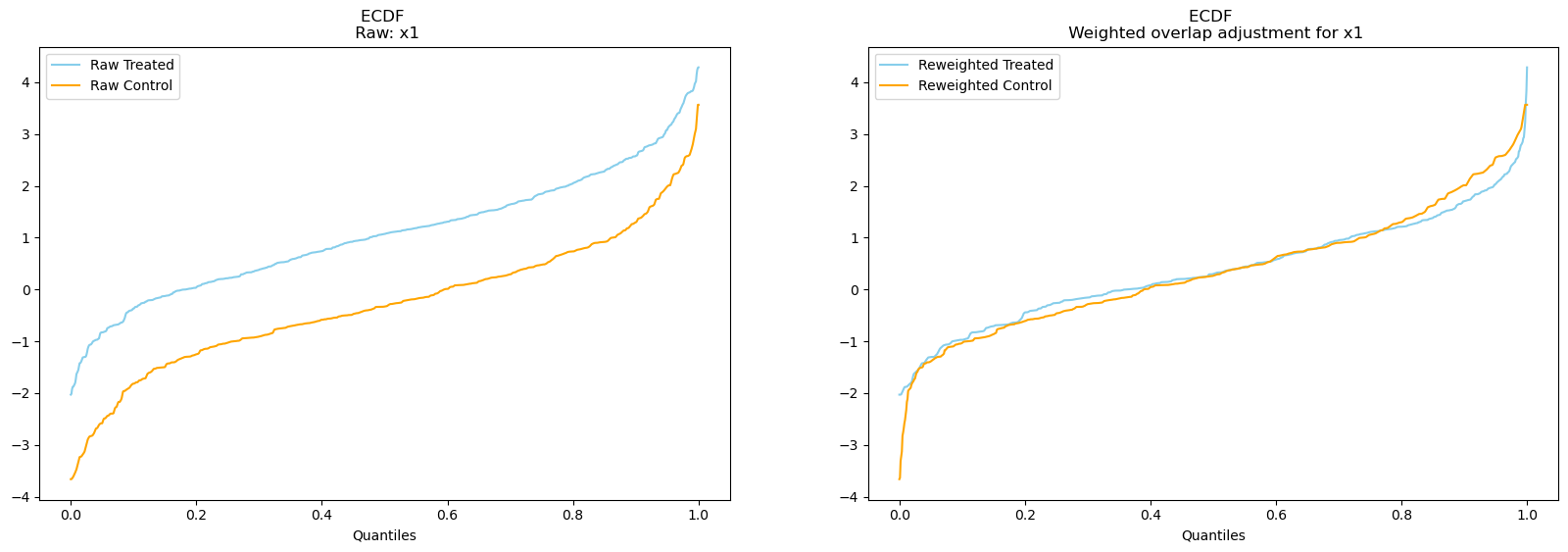
Here we see an even tighter alignment. This weighting scheme refers to the ATO: Average Treatment Effect Among the Overlap Population described in Lucy D’Agostino McGowan’s linked blog. In both cases we can be reasonably happy that conditional on the propensity the weighting mechanism serves to balance the covariate distribution across the treatment effects.
Reminder - by using these propensity scores we are trying to reduce the bias due to selection effects. When the covariate distributions are balanced or close in these plots conditional on our propensity score weighting, we are arguing that this justifies treating the reweighted causal contrast as akin to one derived in an experiment where the treatment assignment mechanism was really random. We are trying to weight our data to recreate the conditions of as-if-random-allocation to the treatment, and use this to appeal to license our causal conclusion. Next we’ll look to estimate the average treatment effect under these schemes and see if we can discern differences in achieved accuracy.
Estimating the Average Treatment Effect#
Again the InversePropensityWeighting class bundles the functionality to inspect the propensity score distribution and evaluate the average treatment effect under different weighting schemes
result1.plot_ate(method="raw", prop_draws=10, ate_draws=500);
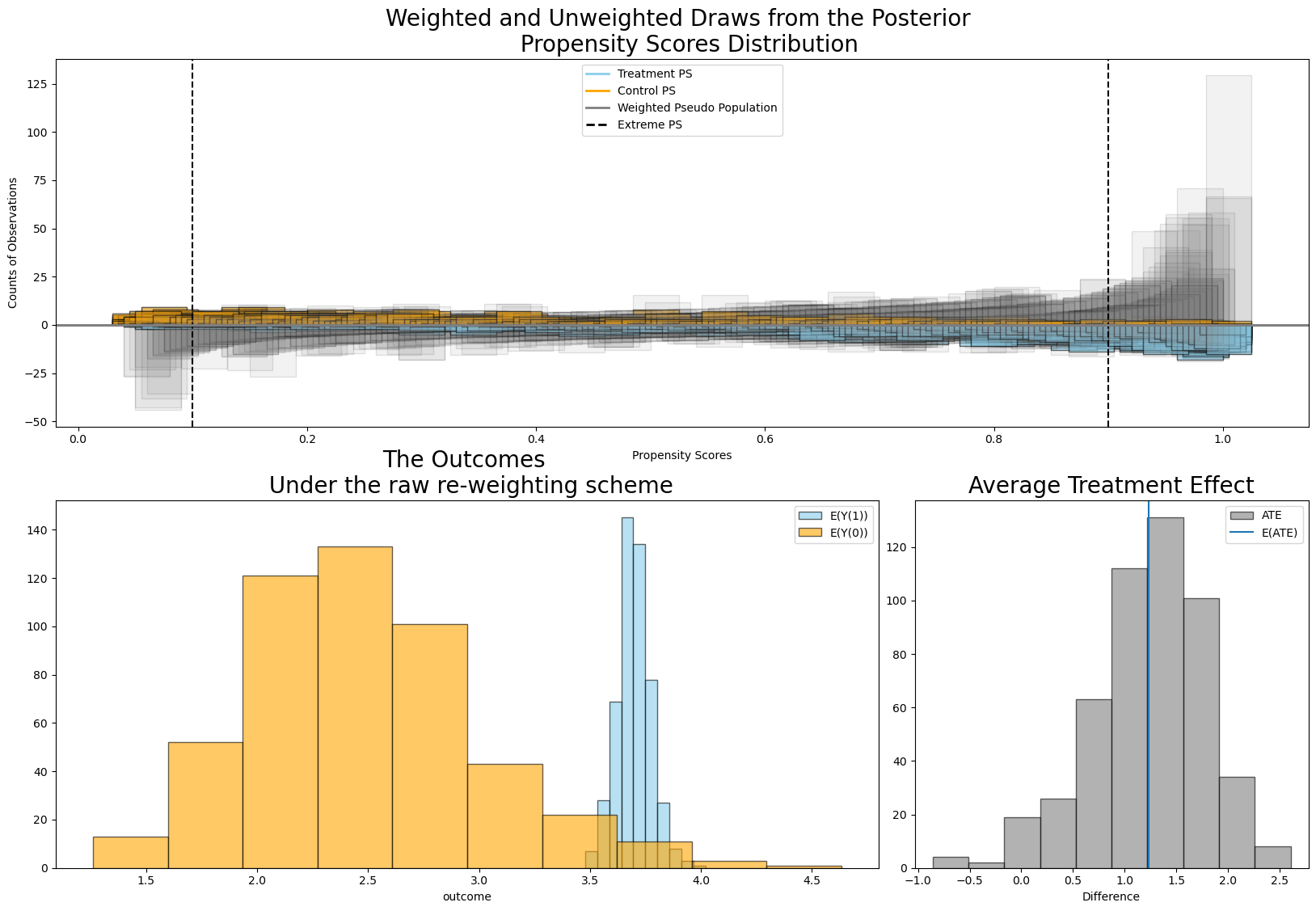
Here we have plotted in three panels:
mirrored draws from the propensity score distribution split by treated and control groups in the yellow and blue with the grey showing the pseudo-population created by the weighting.
the expected outcome in those groups under re-weighting under each draw.
the derived estimates for the average treatment effect.
Note here how expected value of the ATE is pulled slightly away from the true value under this weighting scheme. This is likely due to the high number of individuals with extreme propensity scores - denoted here in the first plot as individuals with propensity scores in excess of .9 and below .1.
Let’s check what happens using the overlap weighting scheme?
result1.plot_ate(method="overlap", prop_draws=10, ate_draws=500);
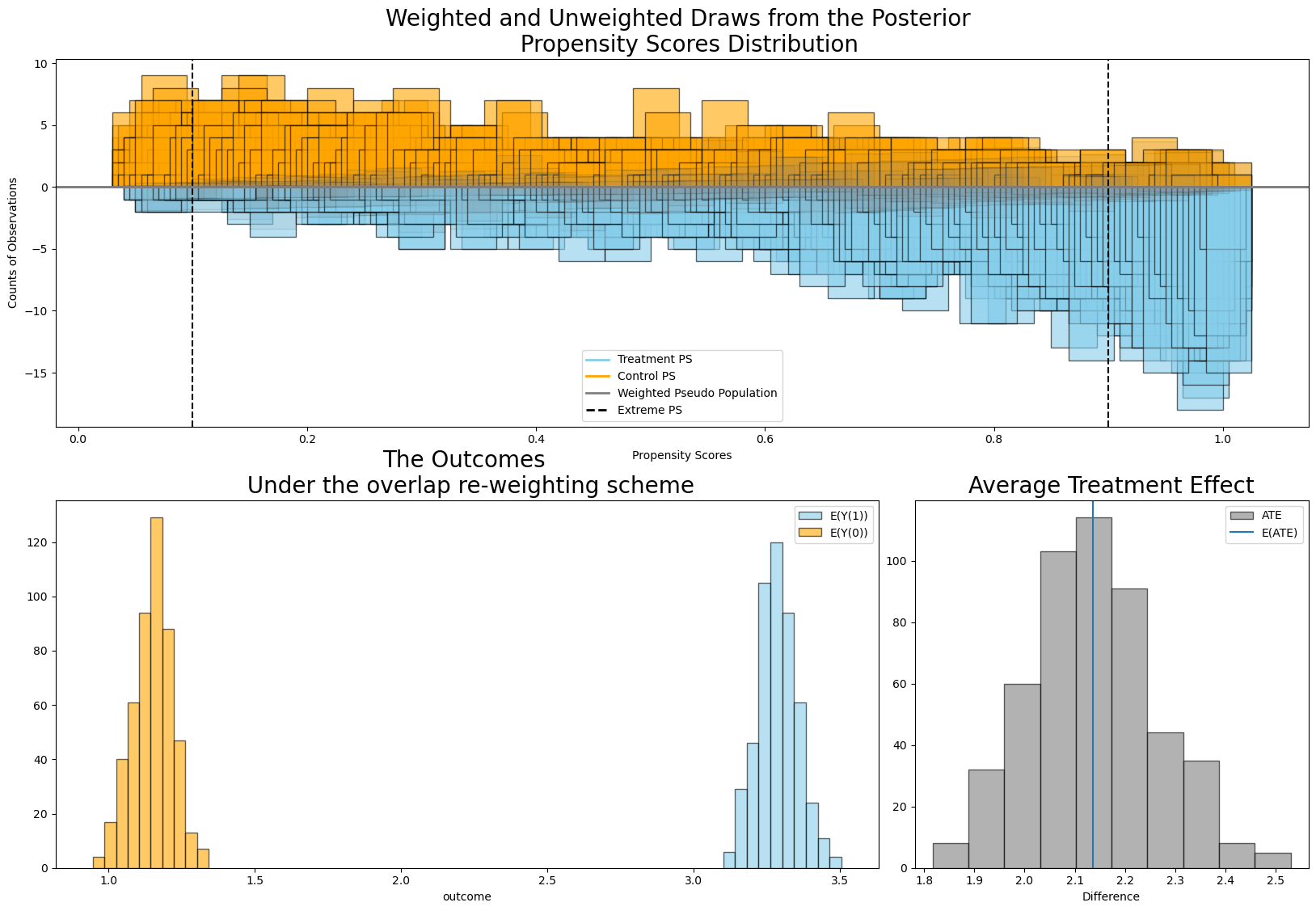
We see here how the particular weighting scheme was able to recover the true treatment effect by defining a contrast in a different pseudo population. This is a useful reminder in that, while propensity score weighting methods are aids to inference in observational data, not all weighting schemes are created equal and we need to be careful in our assessment of when each is applied appropriately. Fundamentally the weighting scheme of choice should be tied to the question of what are you trying to estimate. Aronow and Miller’s Foundations of Agnostic Statistics [Aronow and Miller, 2019] has a good explanation of the differences between the raw, robust and doubly robust weighting schemes. In some sense these offer an escalating series of refined estimators each trying to improve the variance in the ATE estimate. The doubly robust approach also tries to offer some guarantees against model misspecification. The overlap estimator represents an attempt to calculate the ATE among the population with the overlapping propensity scores. This can be used to guard against poor inference in cases where propensity score distributions have large non-overlapping regions.
NHEFS Data#
Now we’ll apply the same techniques to real data.
This data set from the National Health and Nutrition Examination survey records details of weight, activity and smoking habits of around 1500 individuals over two periods. The first period established a baseline and a follow-up period 10 years later. We will analyse whether the individual (trt == 1) quit smoking before the follow up visit. Each individuals’ outcome represents a relative weight gain/loss comparing the two periods.
df = cp.load_data("nhefs")
df_standardised = df.copy()
df_standardised = (df_standardised - df_standardised.mean()) / df_standardised.std()
df_standardised["trt"] = df["trt"]
df_standardised["outcome"] = df["outcome"]
df_standardised[["age", "race", "trt", "smokeintensity", "smokeyrs", "outcome"]].head()
| age | race | trt | smokeintensity | smokeyrs | outcome | |
|---|---|---|---|---|---|---|
| 0 | -0.138421 | 2.568604 | 0 | 0.804858 | 0.367393 | -10.093960 |
| 1 | -0.638846 | -0.389068 | 0 | -0.044645 | -0.048975 | 2.604970 |
| 2 | 1.029237 | 2.568604 | 0 | -0.044645 | 0.117572 | 9.414486 |
| 3 | 2.030086 | 2.568604 | 0 | -1.488800 | 2.365960 | 4.990117 |
| 4 | -0.305229 | -0.389068 | 0 | -0.044645 | -0.465343 | 4.989251 |
formula = """trt ~ 1 + age + race + sex + smokeintensity + smokeyrs + wt71 + active_1 + active_2 +
education_2 + education_3 + education_4 + education_5 + exercise_1 + exercise_2"""
result = cp.InversePropensityWeighting(
df_standardised,
formula=formula,
outcome_variable="outcome",
weighting_scheme="robust", ## Will be used by plots after estimation if no other scheme is specified.
model=cp.pymc_models.PropensityScore(
sample_kwargs={
"draws": 1000,
"target_accept": 0.95,
"random_seed": seed,
"progressbar": False,
},
),
)
result
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [b]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 3 seconds.
Sampling: [b, t_pred]
Sampling: [t_pred]
<causalpy.experiments.inverse_propensity_weighting.InversePropensityWeighting at 0x29e380cd0>
Evaluating Balance#
result.plot_balance_ecdf("age");
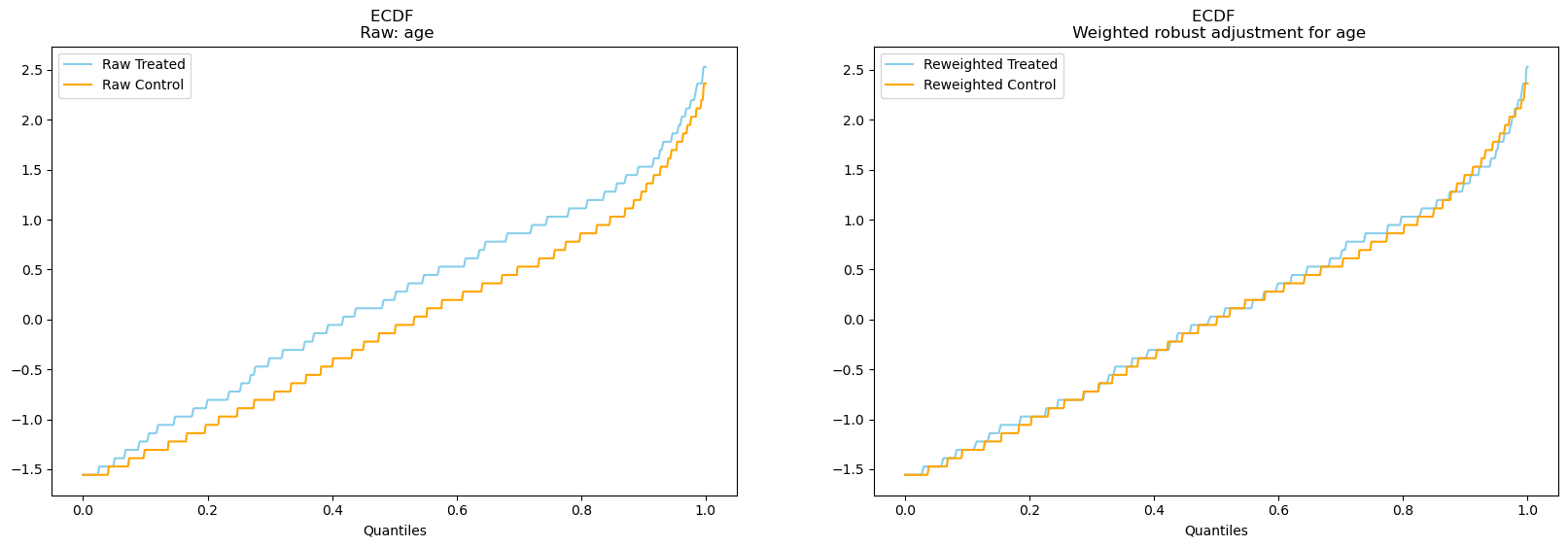
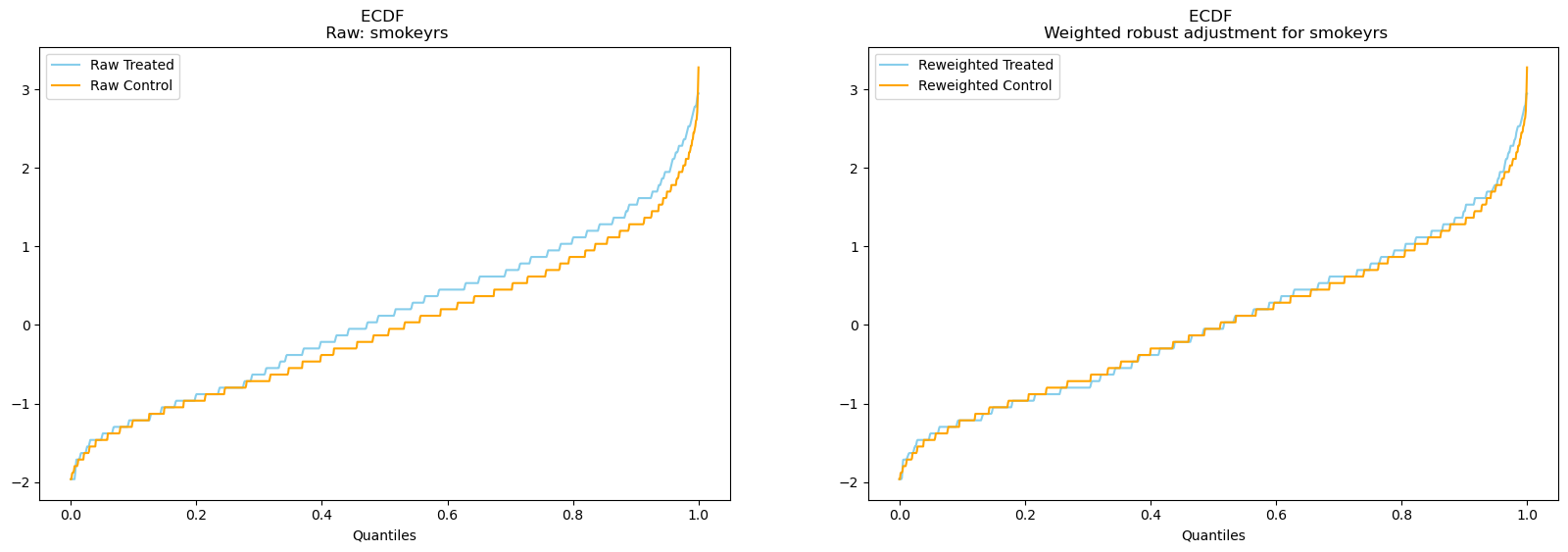
result.plot_balance_ecdf("smokeyrs");
result.plot_balance_ecdf("smokeintensity");
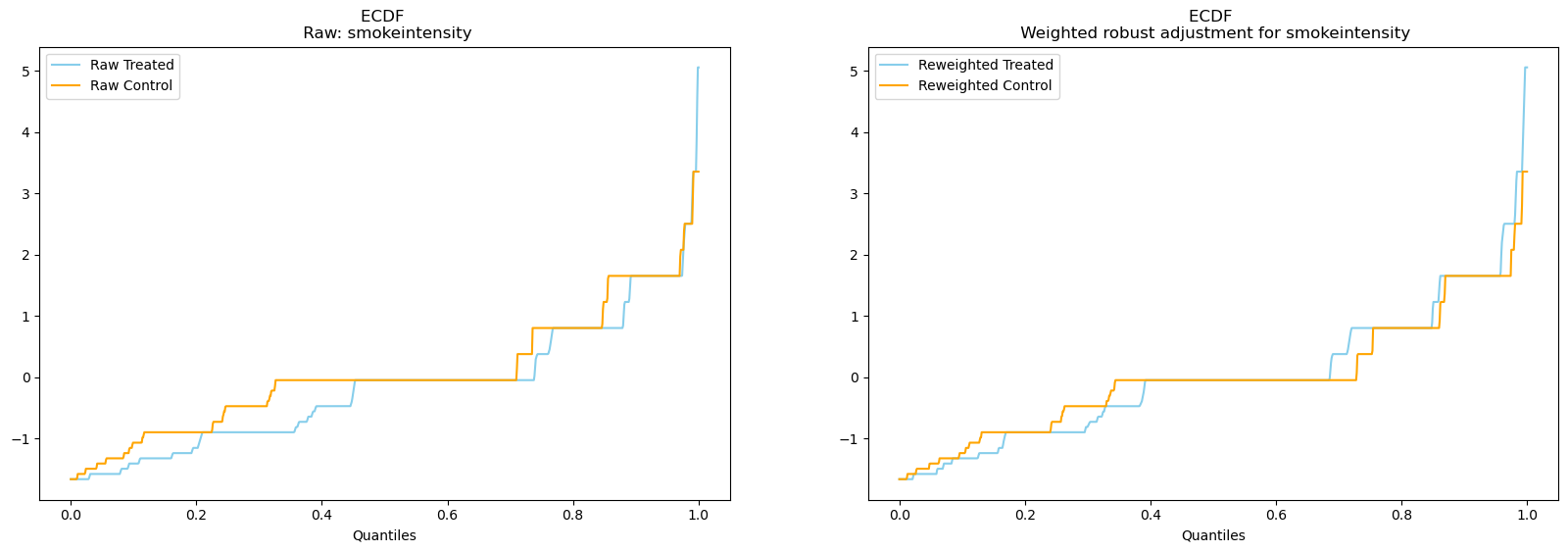
In all cases re-weighting seems to have a positive effect and helps achieve conditional balance.
Estimating the Average Treatment Effect#
Here we’ll use two different weighting schemes to highlight the functionality of the robust and doubly robust weighting. We can use these two approaches by passing in different kwargs to the plotting functions. We are still re-weighting the same propensity score distribution derived with our logit model above.
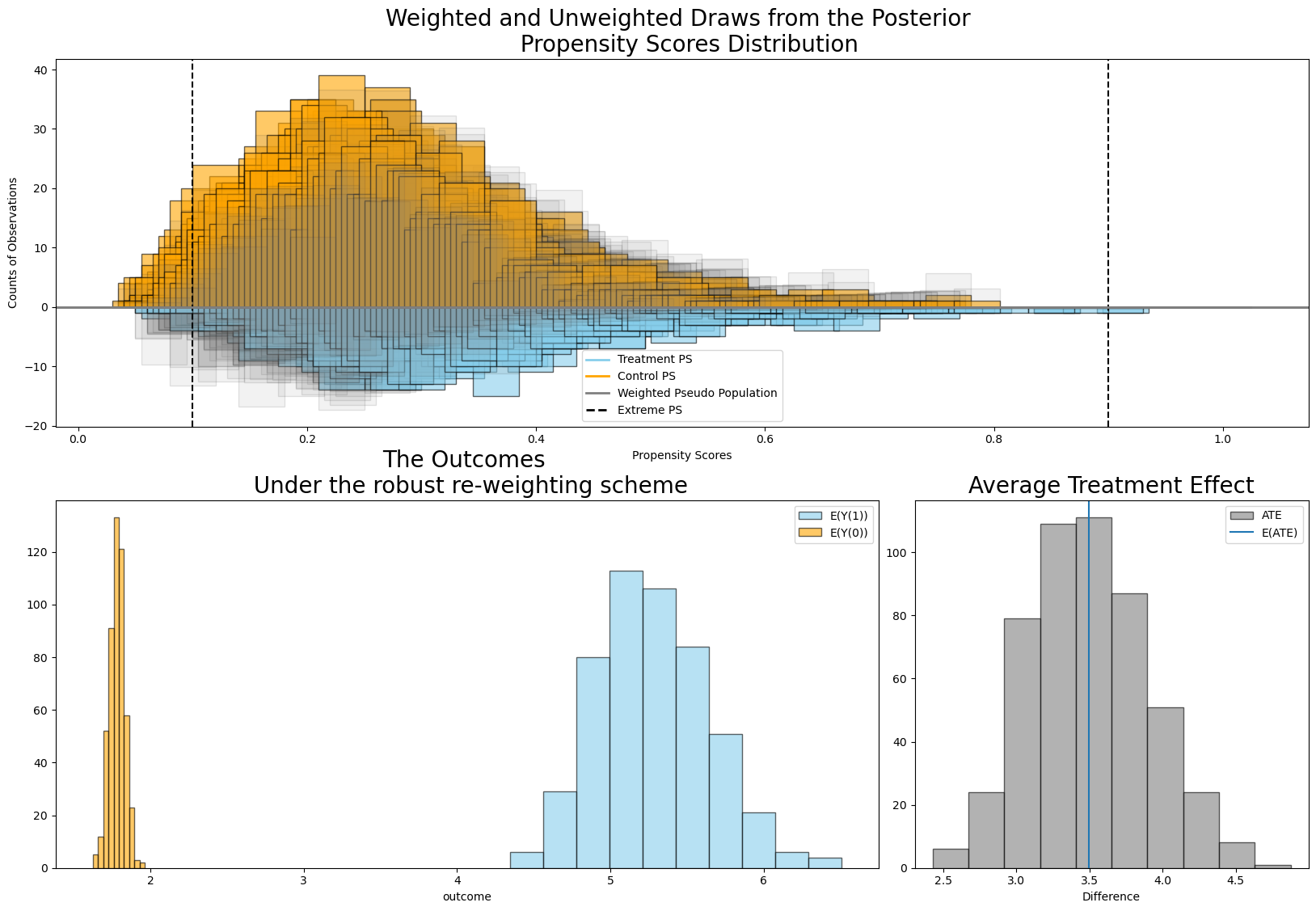
result.plot_ate(method="robust", prop_draws=10, ate_draws=500);
result.plot_ate(method="doubly robust", prop_draws=10, ate_draws=500);
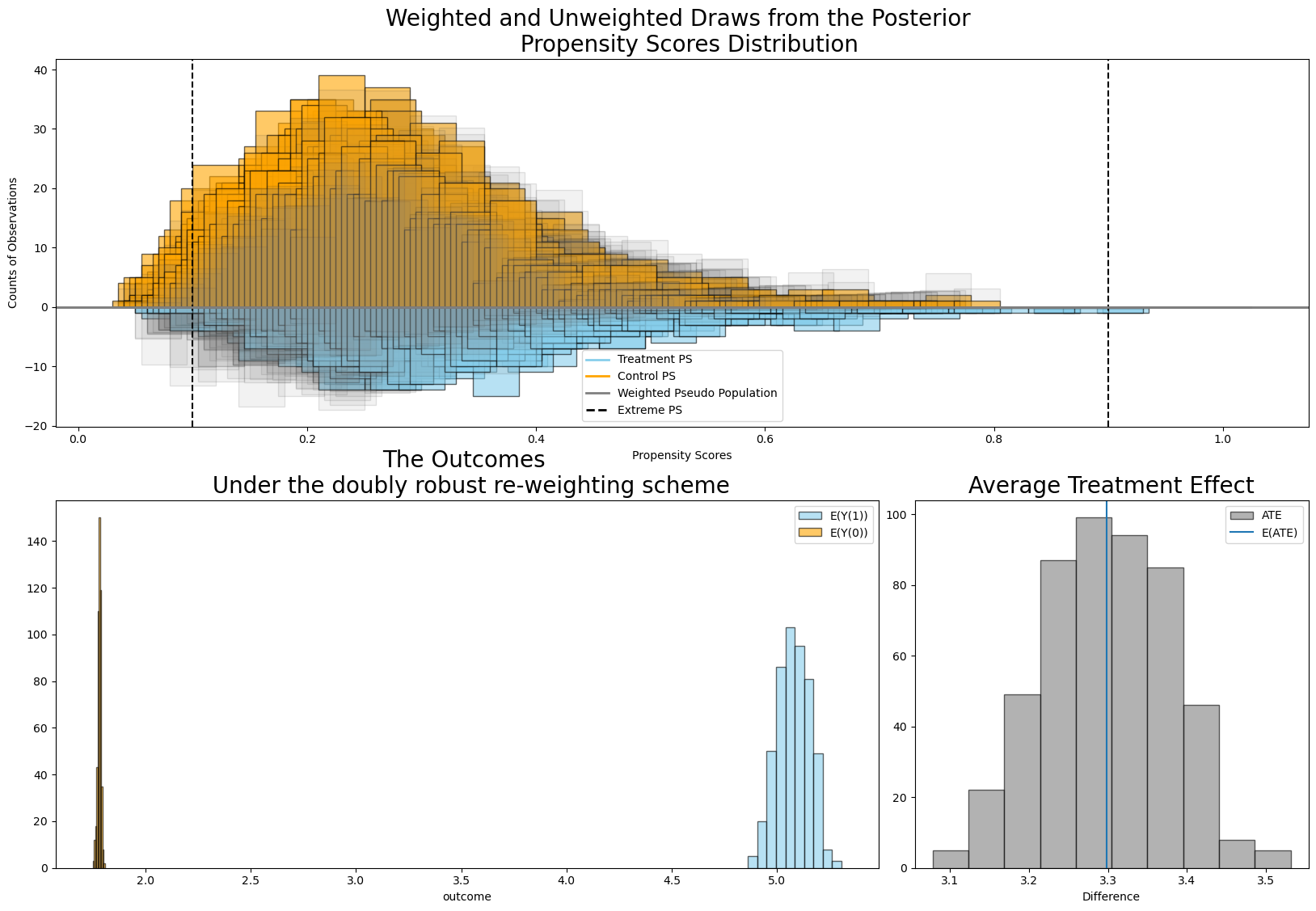
The thing to note here is that while (a) the propensity distributions for both control and treatment groups seem broadly overlapping and (b) both weighting schemes recover substantially similar effects here, the variance on the doubly robust estimator is much tighter. This aspect of the doubly robust estimator is by design and can be important where precise estimation of the treatment effects are important. It will not always be true that the robust and doubly robust weighting schemes will yield similar results, and as such differences between these methods could point to issues with the propensity score model.
Note:
We have limited our focus on the implementation of the inverse propensity score weighting for CausalPy to a simple Logistic regression model of the propensity score. However, the analysis routines of the InversePropensityWeighting experiment class will run on any arviz inference data object where the propensity score posterior distribution can be identified as p. So this frees up the possibility of using non-parametric propensity score designs as discussed in more depth here. [Forde, 2024]
Conclusion#
This concludes our brief tour of inverse-propensity weighting experiments. Propensity modelling and propensity weighting are a powerful tool in causal inference and their potential is by no means limited to the use-cases implemented here. Thinking through the propensity score mechanism and what drives different selection effects is always a good first step in causal modelling. If the drivers of treatment choice can be modelled well propensity score adjustment is often a good way to recover the causal quantity of interest.
We can get nicely formatted tables from our integration with the maketables package.
from maketables import ETable
ETable(result, coef_fmt="b:.3f")