ANCOVA for pre/post treatment nonequivalent group designs#
Note
This is a preliminary example based on synthetic data. It will hopefully soon be updated with data from a real study.
In cases where there is just one pre and one post treatment measurement, it we can analyse data from NEGD experiments using an ANCOVA type approach. The basic model is:
where:
\(i\) represents the \(i^{th}\) unit
\(T_i\) is an indicator variable that treatment was assigned to the \(i^{th}\) unit.
\(pre_i\) and \(post_i\) are the pre and post treatment measurements, respectively.
\(\beta_0\) is an intercept term. Values other than zero indicate change in the untreated group over time.
\(\beta_1\) is the estimated slope of \(pre_i\) upon \(post_i\), and in many cases we would expect this to be around 1.
\(\epsilon_i\) is the residual.
import arviz as az
import matplotlib.pyplot as plt
import seaborn as sns
import causalpy as cp
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = 'retina'
seed = 42
# Set arviz style to override seaborn's default
az.style.use("arviz-darkgrid")
Generate synthetic data#
df = cp.load_data("anova1")
df.head()
| group | pre | post | |
|---|---|---|---|
| 0 | 0 | 8.489252 | 7.824477 |
| 1 | 1 | 12.419854 | 14.796265 |
| 2 | 0 | 11.131001 | 10.693495 |
| 3 | 0 | 10.503789 | 10.532153 |
| 4 | 0 | 10.599761 | 9.731500 |
Let’s visualise this data in two different ways.
_, ax = plt.subplots(1, 2, figsize=(11, 5))
# ANCOVA plot
ax[0].axline((7, 7), (15, 15), color="k")
sns.scatterplot(x="pre", y="post", hue="group", alpha=0.5, data=df, ax=ax[0])
ax[0].set_title("ANCOVA style plot")
# Difference-in-difference plot
df_did = df.assign(unit=lambda x: x.index).melt(
id_vars=["group", "unit"], var_name="time", value_name="value"
)
sns.lineplot(
df_did,
x="time",
y="value",
hue="group",
units="unit",
estimator=None,
alpha=0.25,
ax=ax[1],
)
ax[1].set_title("Difference-in-difference style plot");
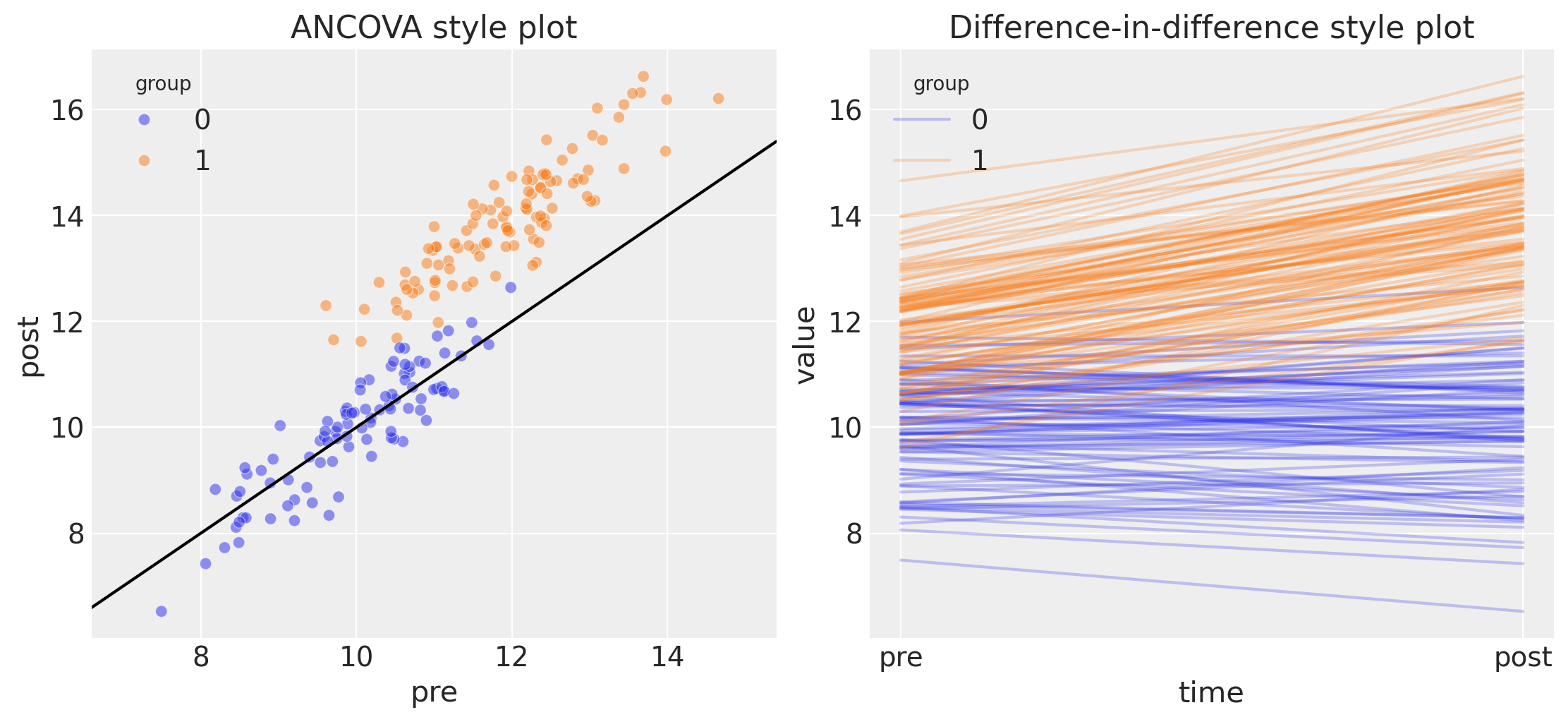
The plot on the left is the most relevant for conducting an ANCOVA style analysis. Pre and post measures are on the x and y axes, respectively. This plot shows a number of things:
The pre treatment measurement for the control group is lower than for the treatment group, which is consistent with the idea that we have non-random allocation of units to the treatment and control group.
The control group points lying on the line of unity suggest that the control group was unaffected by the treatment.
The treatment group scores higher on the post treatment score, shown by the points lying above the line of unity. So visually, we suspect that the treatment caused an increase in the outcome metric.
Of course, many different patterns of result are possible, but we can use the same approach to get a quick visual interpretation of the data.
The plot on the right is of exactly the same data, but plotted in a way which clearly demonstrates the similarity to the difference in differences analysis approach. We don’t delve into that more here, but see the difference in difference examples for more on this.
Run the analysis#
Note
The random_seed keyword argument for the PyMC sampler is not necessary. We use it here so that the results are reproducible.
result = cp.PrePostNEGD(
df,
formula="post ~ 1 + C(group) + pre",
group_variable_name="group",
pretreatment_variable_name="pre",
model=cp.pymc_models.LinearRegression(sample_kwargs={"random_seed": seed}),
)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta, y_hat_sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
Sampling: [beta, y_hat, y_hat_sigma]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
fig, ax = result.plot()
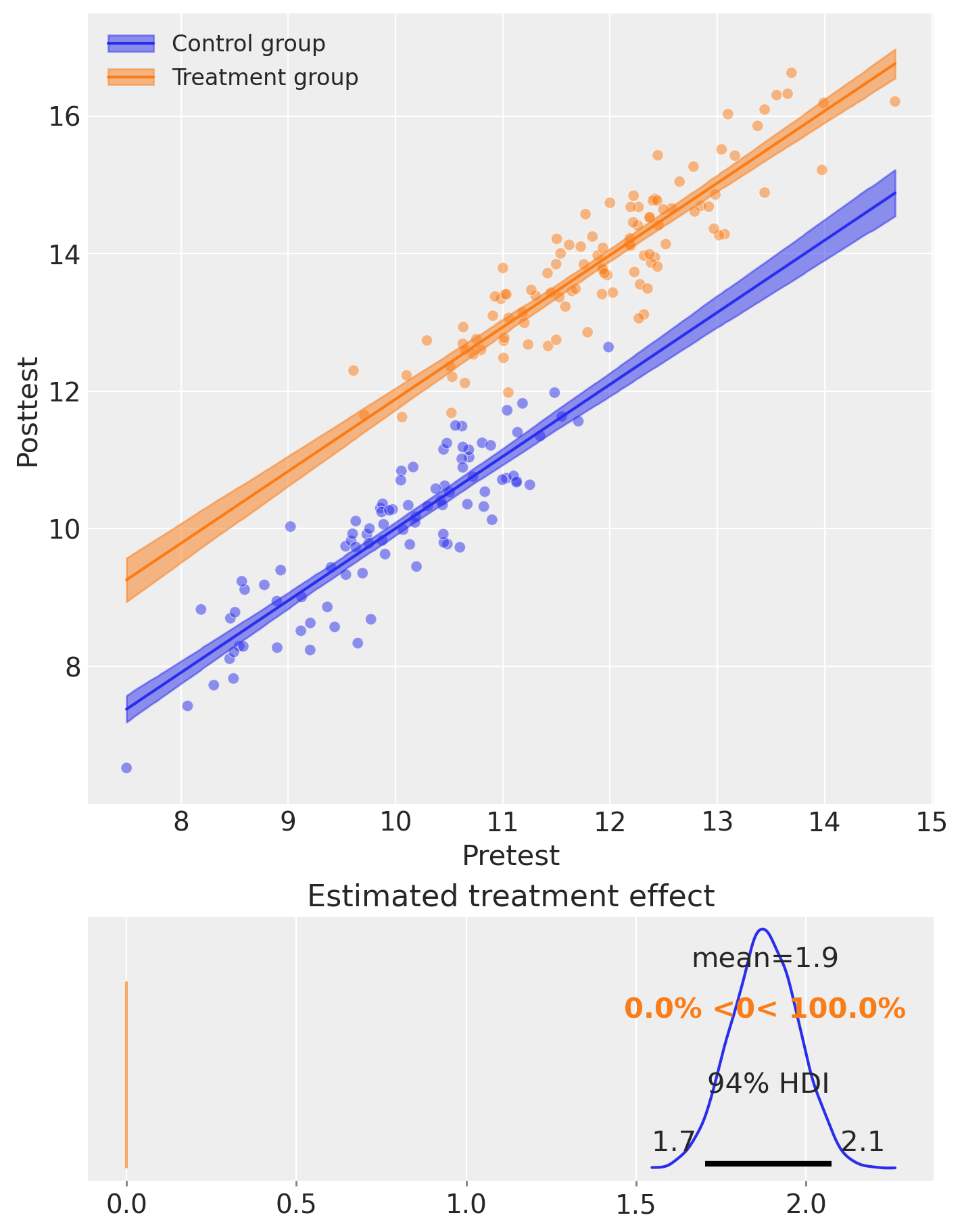
result.summary()
==================Pretest/posttest Nonequivalent Group Design===================
Formula: post ~ 1 + C(group) + pre
Results:
Causal impact = 1.9, $CI_{94%}$[1.7, 2.1]
Model coefficients:
Intercept -0.47, 94% HDI [-1.2, 0.22]
C(group)[T.1] 1.9, 94% HDI [1.7, 2.1]
pre 1, 94% HDI [0.98, 1.1]
y_hat_sigma 0.51, 94% HDI [0.46, 0.56]
Effect Summary Reporting#
For decision-making, you often need a concise summary of the causal effect. The effect_summary() method provides a decision-ready report with key statistics. Note that for ANCOVA (pretest/posttest nonequivalent group designs), the effect is a single scalar (treatment effect), similar to Difference-in-Differences.
# Generate effect summary
stats = result.effect_summary()
stats.table
| mean | median | hdi_lower | hdi_upper | p_gt_0 | |
|---|---|---|---|---|---|
| treatment_effect | 1.879747 | 1.879853 | 1.688983 | 2.075447 | 1.0 |
# View the prose summary
print(stats.text)
The average treatment effect was 1.88 (95% HDI [1.69, 2.08]), with a posterior probability of an increase of 1.000.
# You can specify the direction of interest (e.g., testing for an increase)
stats_increase = result.effect_summary(direction="increase")
stats_increase.table
| mean | median | hdi_lower | hdi_upper | p_gt_0 | |
|---|---|---|---|---|---|
| treatment_effect | 1.879747 | 1.879853 | 1.688983 | 2.075447 | 1.0 |
We can get nicely formatted tables from our integration with the maketables package.
from maketables import ETable
ETable(result, coef_fmt="b:.3f")
| post | |
|---|---|
| (1) | |
| coef | |
| group=1 | 1.880 |
| pre | 1.047 |
| Intercept | -0.469 |
| stats | |
| N | 200 |
| Format of coefficient cell: Coefficient | |