Drinking age - Bayesian analysis#
This example uses the sharp regression discontinuity design to make claims about the causal effects of the minimum legal drinking age (21 in the USA) upon all cause mortality rates. The dataset is from a study by Carpenter and Dobkin [2009].
import arviz as az
import matplotlib.pyplot as plt
import causalpy as cp
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = 'retina'
seed = 42
# Set arviz style to override seaborn's default
az.style.use("arviz-darkgrid")
Load and process data.
df = (
cp.load_data("drinking")
.rename(columns={"agecell": "age"})
.assign(treated=lambda df_: df_.age > 21)
)
Main effects model#
First we will examine a simple ‘main effects’ model. Here, the expected death rate (in units of deaths/1000 people/year) for a given age \(a\) (with monthly resolution), is modelled with an intercept term \(\beta_0\), a treatment effect \(\beta_1\) and an effect of age \(\beta_2\).
The term \(t(a)\) describes whether ‘treatment’ has been applied. In this example it simply describes whether a give age \(a\) is over the minimum legal drinking age of 21:
To be clear, \(\beta_2 a\) describes a linear trend of how expected mortality rate changes with age. The coefficient \(\beta_0\) is the intercept of this linear trend (at \(a=0\)). This leaves \(\beta_1 t(a)\) which we can understand as modelling the discontinuity of the linear trend around the age threshold.
Note
The random_seed keyword argument for the PyMC sampler is not necessary. We use it here so that the results are reproducible.
result = cp.RegressionDiscontinuity(
df,
formula="all ~ 1 + age + treated",
running_variable_name="age",
model=cp.pymc_models.LinearRegression(
sample_kwargs={"target_accept": 0.95, "random_seed": seed}
),
treatment_threshold=21,
)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta, y_hat_sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 7 seconds.
Sampling: [beta, y_hat, y_hat_sigma]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
For decision-making, you often need a concise summary of the causal effect. The effect_summary() method provides a decision-ready report with key statistics. For Regression Discontinuity, the effect is the discontinuity (jump) at the threshold.
stats = result.effect_summary()
stats.table
| mean | median | hdi_lower | hdi_upper | p_gt_0 | |
|---|---|---|---|---|---|
| discontinuity | 6.983609 | 6.998871 | 4.286134 | 9.615931 | 1.0 |
print(stats.text)
The discontinuity at threshold was 6.98 (95% HDI [4.29, 9.62]), with a posterior probability of an increase of 1.000.
fig, ax = result.plot()
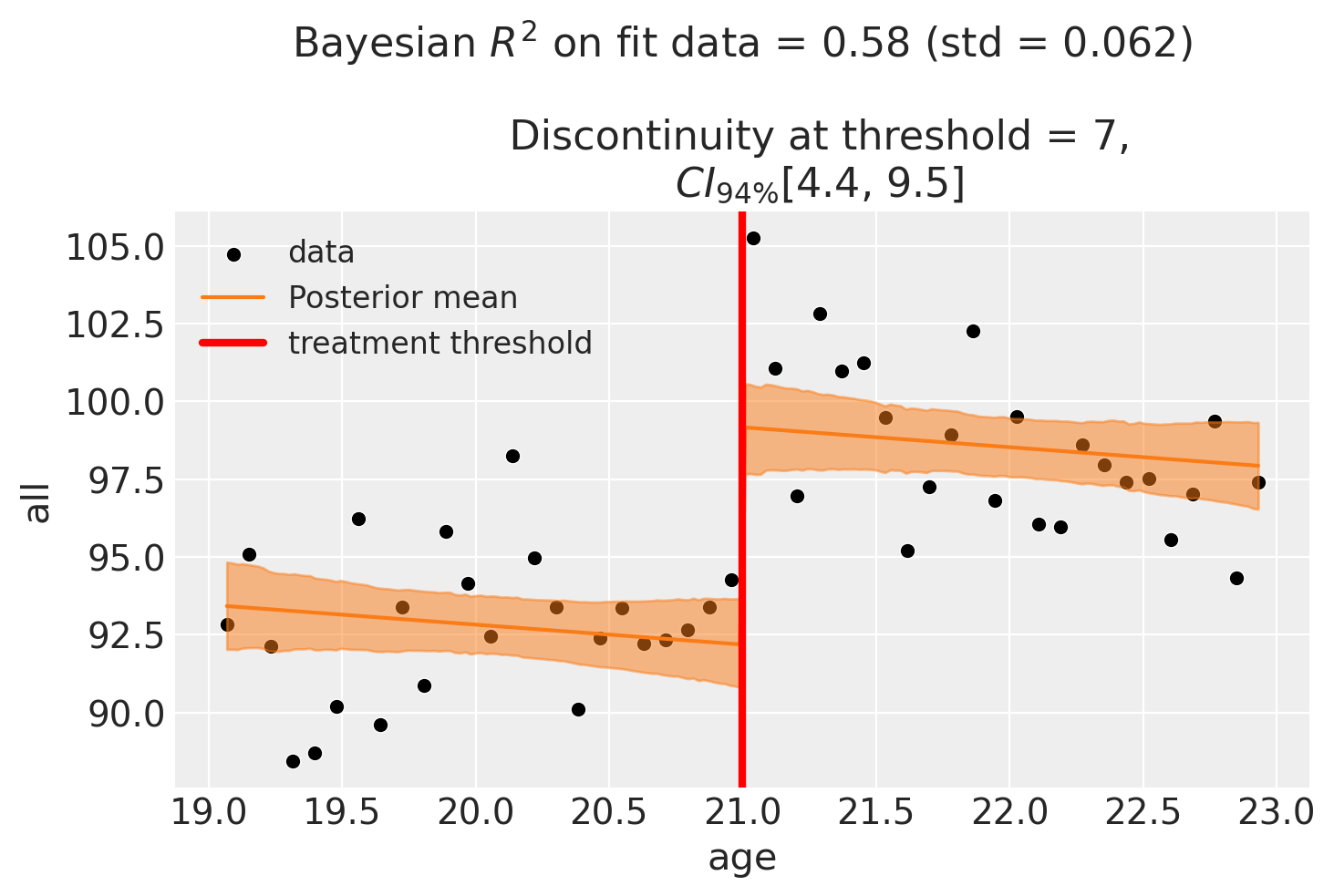
And let’s grab the text summary of the results.
result.summary()
Regression Discontinuity experiment
Formula: all ~ 1 + age + treated
Running variable: age
Threshold on running variable: 21
Bandwidth: inf
Donut hole: 0.0
Observations used for fit: 48
Results:
Discontinuity at threshold = 6.98$CI_{94\%}$[4.4, 9.5]
Model coefficients:
Intercept 106, 94% HDI [83, 128]
treated[T.True] 7, 94% HDI [4.4, 9.5]
age -0.64, 94% HDI [-1.7, 0.49]
y_hat_sigma 2.4, 94% HDI [2, 2.9]
In this main effects model, the size of the causal effect is equal to our posterior estimate of \(\beta_1\). Let’s plot the parameter estimates (left) and zoom in on the posterior distribution for the main effect of treatment (right).
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
az.plot_forest(result.idata.posterior, var_names="beta", ax=ax[0])
az.plot_posterior(
result.idata.posterior.beta.sel(coeffs="treated[T.True]"),
round_to=3,
ax=ax[1],
)
ax[1].set(title="treated[T.True]")
fig
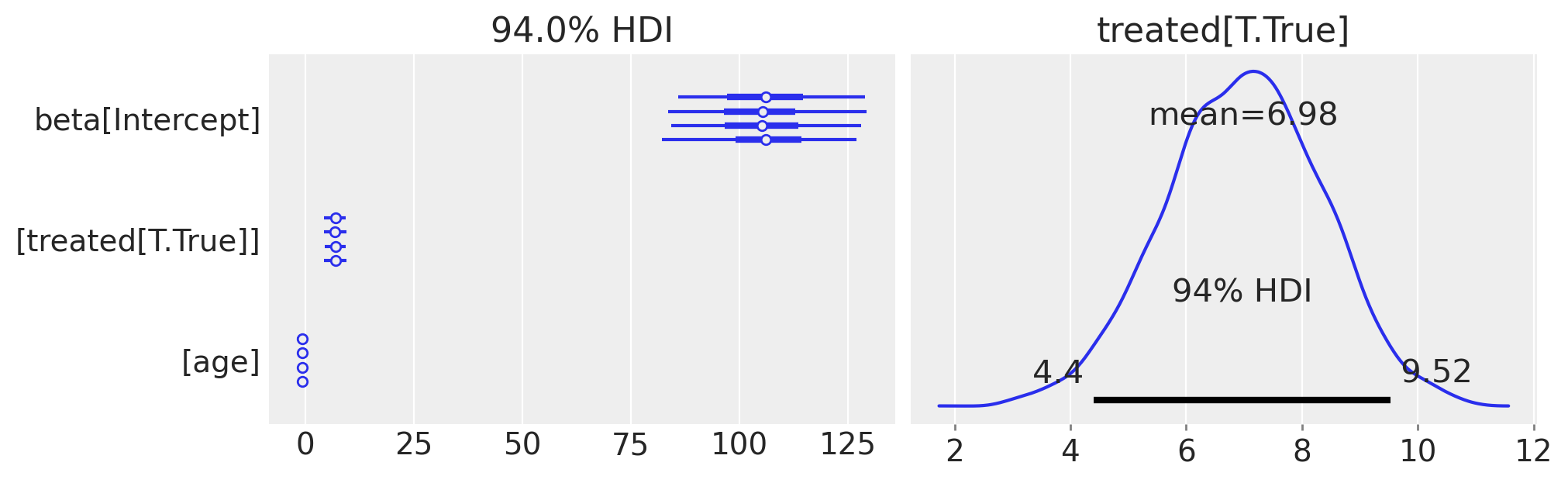
We can see that this matches up (nearly exactly) with the “discontinuity at threshold” figures in the first results figure.
It is not exactly the same because we actually manually calculate the discontinuity at threshold. The reason for this is because in anything but the simplest model, the discontinuity at threshold is not simply equal to this parameter. In order to understand this, let’s look at the marginally more complex model where we incorporate an interaction term.
Interaction model#
We add an interaction term by changing our formula to all ~ 1 + age + treated + age:treated. This now changes the statistical model to :
This model is now more complex in that it can allow for the trend in mortality rate to vary before versus after the age of 21 if the data suggest it. If it is not clear already, it will be clear from the next results figure that the discrepancy at threshold is no longer equal to the \(\beta_1\) coefficient. Let’s run the model and see.
result2 = cp.RegressionDiscontinuity(
df,
formula="all ~ 1 + age + treated + age:treated",
running_variable_name="age",
model=cp.pymc_models.LinearRegression(sample_kwargs={"random_seed": seed}),
treatment_threshold=21,
)
fig, ax = result2.plot()
fig
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta, y_hat_sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 9 seconds.
There were 130 divergences after tuning. Increase `target_accept` or reparameterize.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Sampling: [beta, y_hat, y_hat_sigma]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
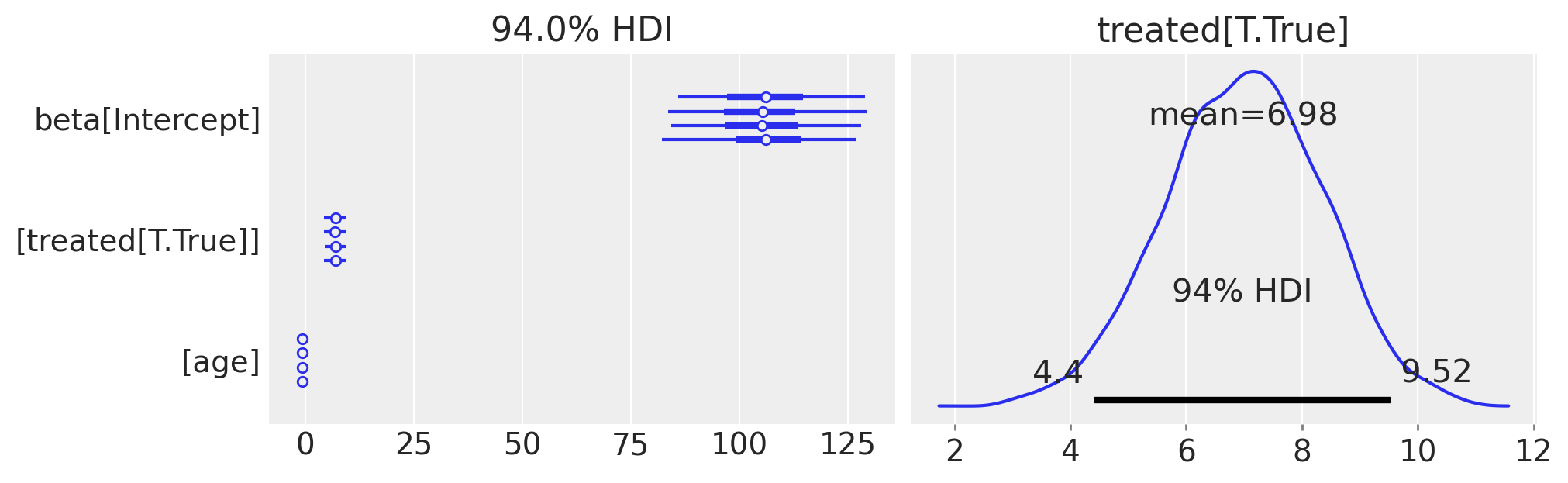
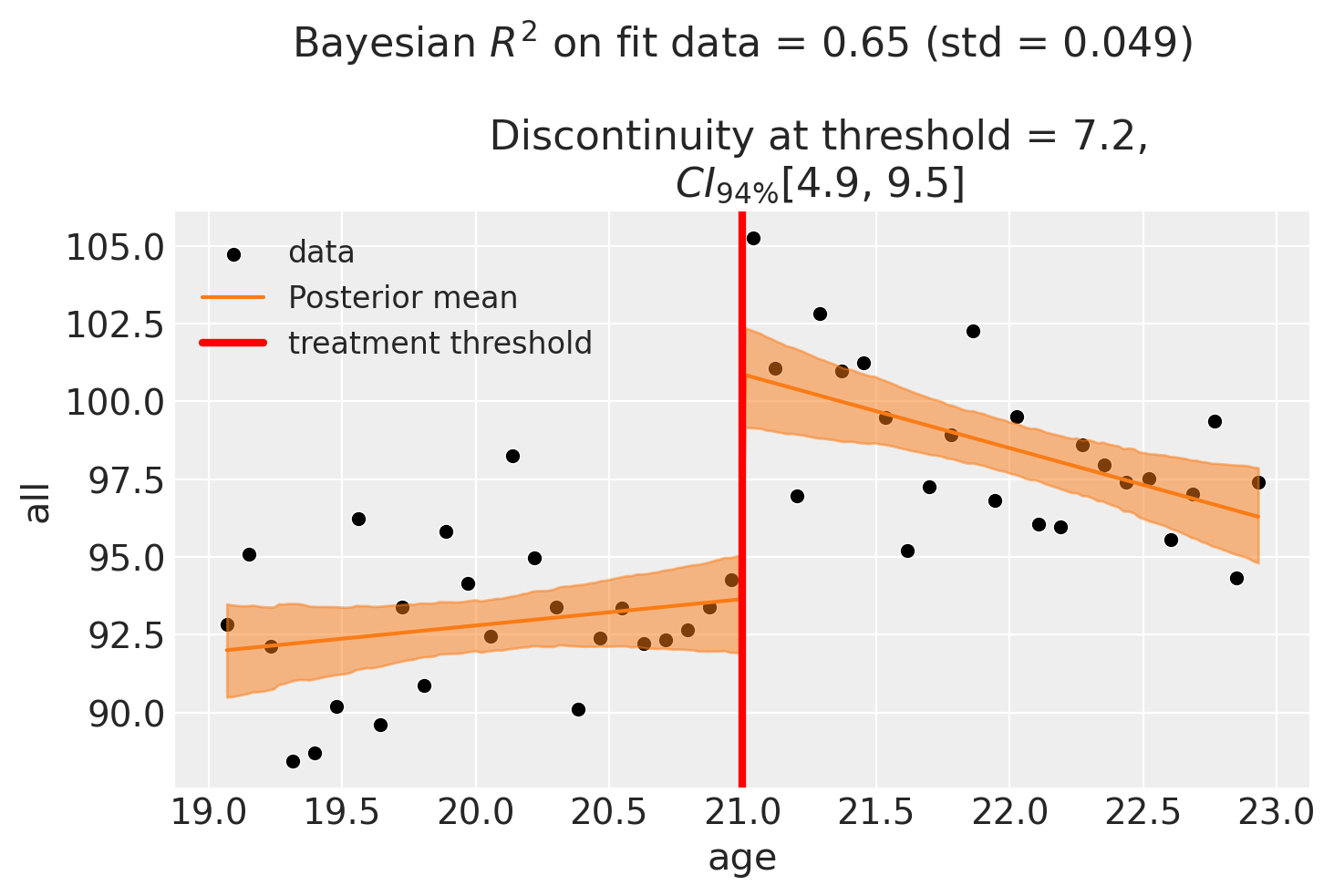
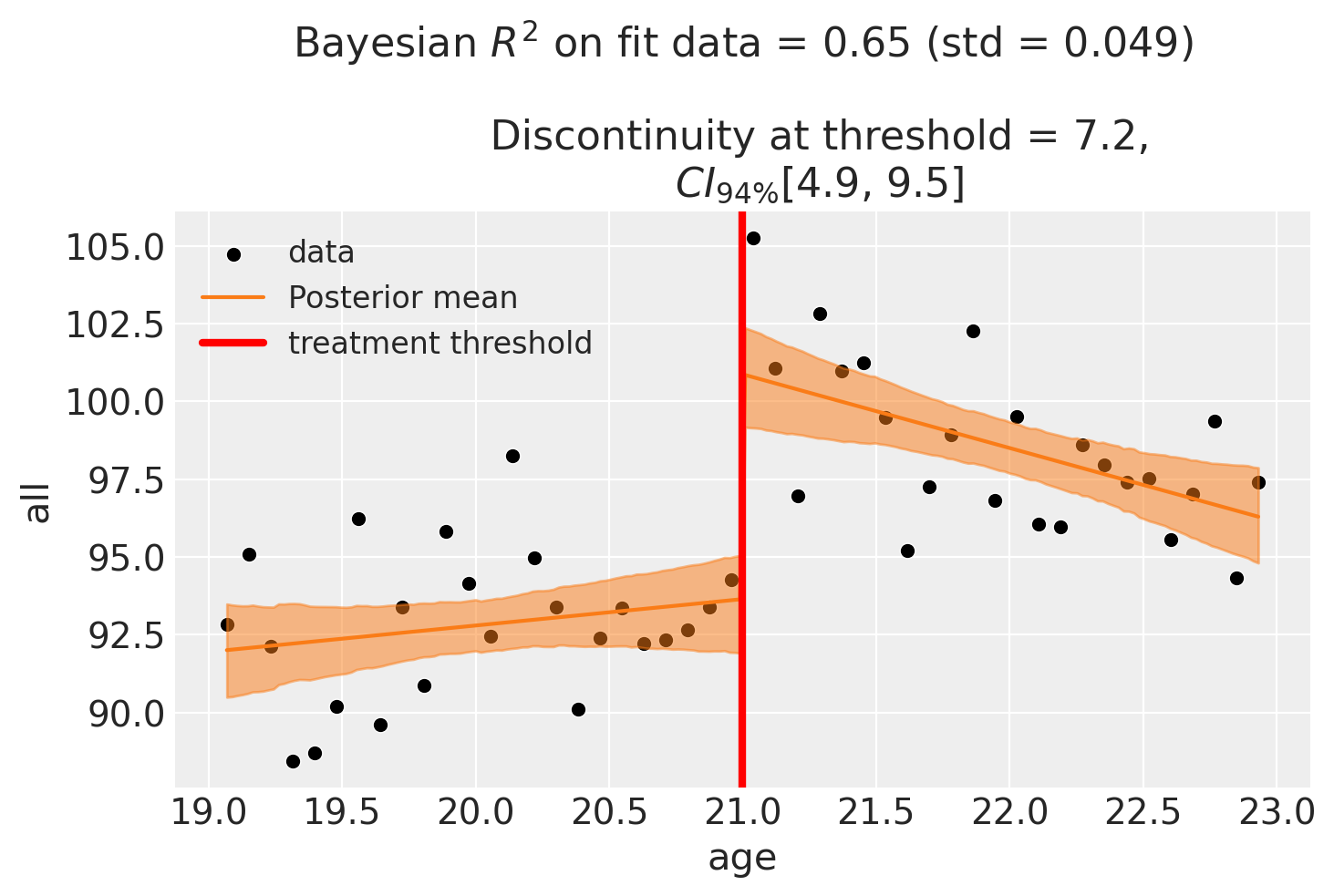
We can now see that by adding an interaction term, the parameter estimates are now much changed, and the estimated discontinuity at threshold is no longer simply given by the \(\beta_1\) parameter. To confirm this, we can check the estimate of \(\beta_1\) (which corresponds to the treated[T.True] coefficient).
az.plot_forest(result2.idata.posterior, var_names="beta", figsize=(10, 3))
display(fig)
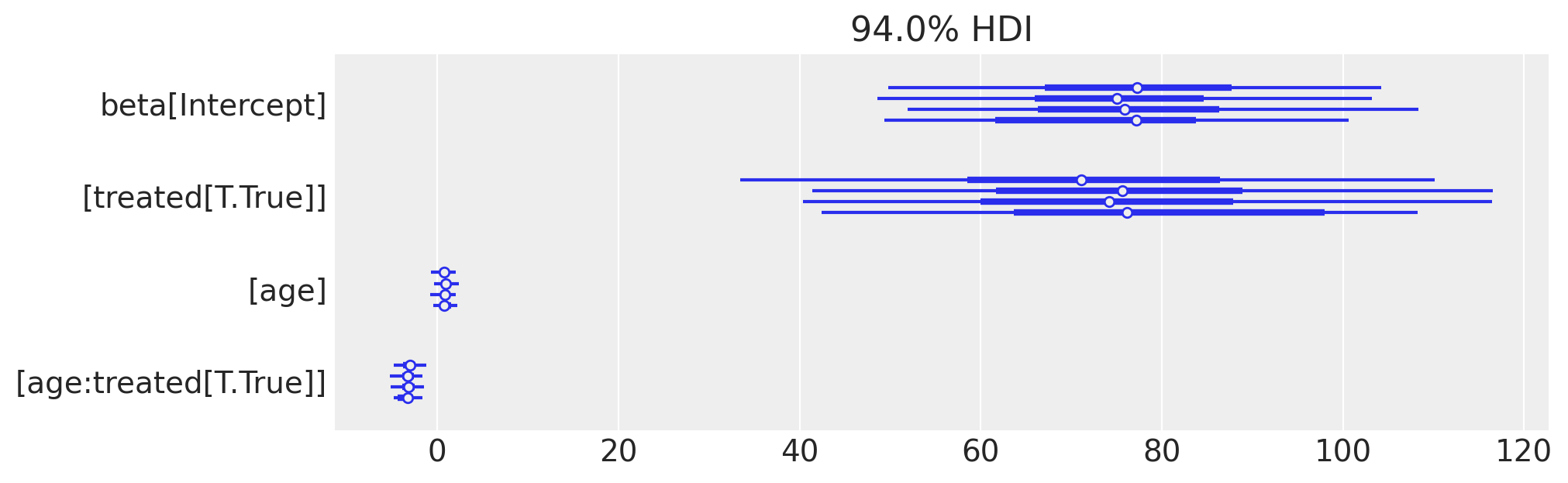
We can see that this estimate is now wildly off the desired “discontinuity at threshold” value. It is for this reason that CausalPy manually calculates the “discontinuity at threshold” by evaluating the difference in predicted outcome values slightly above versus slightly below the treatment threshold.
We can get a decision-ready summary of the causal effect for this interaction model:
stats2 = result2.effect_summary()
stats2.table
| mean | median | hdi_lower | hdi_upper | p_gt_0 | |
|---|---|---|---|---|---|
| discontinuity | 7.225445 | 7.214937 | 4.78268 | 9.669601 | 1.0 |
Centering the running variable on the treatment threshold#
Another practice to deal with this is to centre the running variable on the threhsold such that the threshold (minimum legal drinking age) is now at zero. This also makes the parameters more interpretable.
df["age"] = df["age"] - 21
result3 = cp.RegressionDiscontinuity(
df,
formula="all ~ 1 + age + treated + age:treated",
running_variable_name="age",
model=cp.pymc_models.LinearRegression(sample_kwargs={"random_seed": seed}),
treatment_threshold=0,
)
fig, ax = result3.plot()
display(fig)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta, y_hat_sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
Sampling: [beta, y_hat, y_hat_sigma]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
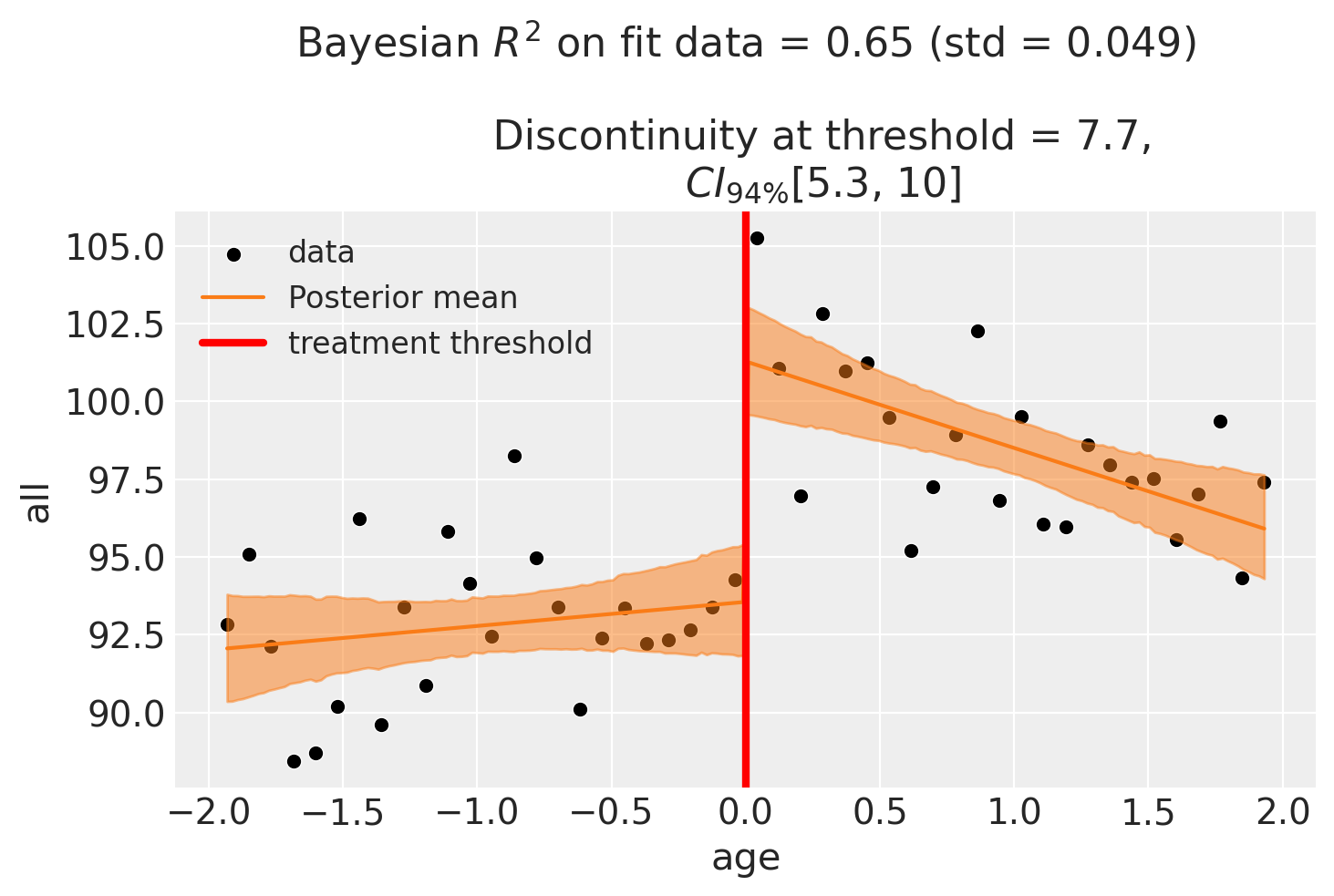
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
az.plot_forest(result3.idata.posterior, var_names="beta", ax=ax[0])
az.plot_posterior(
result3.idata.posterior.beta.sel(coeffs="treated[T.True]"),
round_to=3,
ax=ax[1],
)
ax[1].set(title="treated[T.True]")
display(fig)
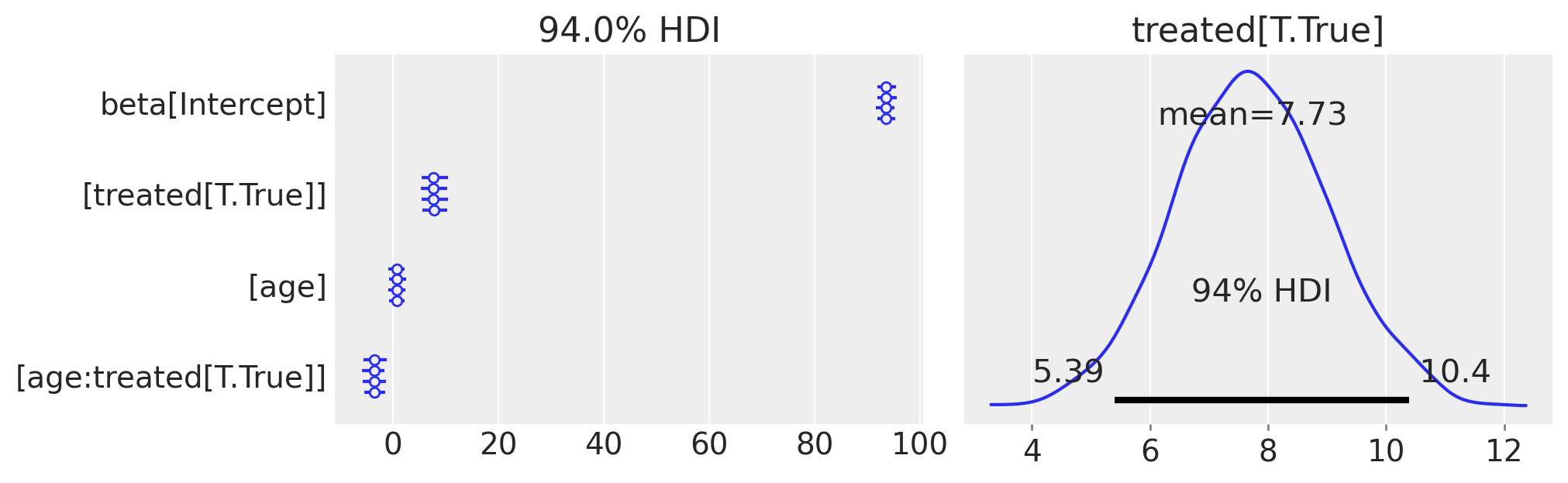
And the effect summary for the centered model:
stats3 = result3.effect_summary()
stats3.table
| mean | median | hdi_lower | hdi_upper | p_gt_0 | |
|---|---|---|---|---|---|
| discontinuity | 7.728023 | 7.708312 | 5.260876 | 10.445952 | 1.0 |
We can get nicely formatted tables from our integration with the maketables package.
from maketables import ETable
ETable([result, result2, result3], coef_fmt="b:.3f")
| all | |||
|---|---|---|---|
| (1) | (2) | (3) | |
| coef | |||
| treated=True | 6.985 | 74.822 | 7.730 |
| age | -0.641 | 0.849 | 0.774 |
| age × treated=True | -3.219 | -3.557 | |
| Intercept | 105.640 | 75.821 | 93.558 |
| stats | |||
| N | 48 | 48 | 48 |
| Bayesian R2 | 0.576 | 0.646 | 0.655 |
| Format of coefficient cell: Coefficient | |||