Bayesian geolift with CausalPy#
This notebook covers how to use CausalPy’s Bayesian synthetic control functionality to assess ‘geolift’. Our hypothetical scenario is:
We are a data scientist within a company that operates over Europe. We have been given a historical dataset of sales volumes, in units of 1000’s. The data is broken down by country and was collected at weekly frequency. We have data for the past 4 years.
At the start of 2022, the marketing department decided to refurbish all the stores in Denmark. Now, at the end of 2022, the company wants you to assess whether this refurbishment programme increased sales. If you tell them that the store refurbishment scheme increased sales volumes then they will roll out the scheme to other countries. Nobody said this, but in the back of your mind you worry that if you tell them that refurbishments increase sales but that doesn’t actually happen in the future, then the companies profits will drop, the value of your shares will decrease, and your job security may be at risk.
Your boss is pretty tuned in. She also has these concerns. She knows that while it might be easy to establish an association between the store refurbishments and changes in sales volumes, we really want to know if the store refurbishments caused an increase in sales.
We know that the best way to make causal claims is to run a randomized control trial (sometimes known as an A/B test). If we have randomly assigned stores across Europe (or picked a country) at random, then perhaps an A/B test would do the job. But we did not pick Denmark at random - so we are worried about confounding variables.
But we heard about synthetic control methods and a thing called GeoLift. After some research, we decide this is exactly what we want to do. But we are particularly interested in how certain we are in the level of any uplift we detect, so we want to use Bayesian methods and get easy to interpret Bayesian credible intervals. You find a library called
CausalPythat supports exactly that use case and are delighted.
Let’s go!
import arviz as az
import pandas as pd
import causalpy as cp
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = 'retina'
pd.set_option("display.precision", 2)
seed = 42
Load the dataset#
CausalPy includes an example (simulated) dataset suitable to explore ideas around geographical lift testing. All we need to do is to load that, get our observation dates set up appropriately in a pandas dataframe, and define the treatment time.
df = (
cp.load_data("geolift1")
.assign(time=lambda x: pd.to_datetime(x["time"]))
.set_index("time")
)
treatment_time = pd.to_datetime("2022-01-01")
df.head()
| Austria | Belgium | Bulgaria | Croatia | Cyprus | Czech_Republic | Estonia | Finland | Greece | Hungary | Denmark | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| time | |||||||||||
| 2019-01-06 | 2.15 | 2.50 | 1.49 | 2.77 | 2.00 | 2.23 | 1.96 | 2.82 | 5.36 | 1.71 | 2.39 |
| 2019-01-13 | 2.03 | 2.46 | 1.44 | 2.60 | 1.90 | 2.22 | 1.90 | 2.72 | 5.47 | 1.93 | 2.21 |
| 2019-01-20 | 1.99 | 2.14 | 1.34 | 2.71 | 1.55 | 2.05 | 1.67 | 2.56 | 5.33 | 1.86 | 2.18 |
| 2019-01-27 | 1.85 | 2.04 | 1.34 | 2.40 | 1.71 | 2.14 | 1.62 | 2.47 | 5.23 | 1.83 | 1.97 |
| 2019-02-03 | 1.75 | 1.78 | 1.09 | 2.49 | 1.45 | 2.18 | 1.44 | 2.41 | 5.24 | 1.91 | 1.92 |
In our dataset, columns represent the different European countries that we operate in. We also have an index which labels each row with the date - the observations are weekly in frequency. The values in the table represent the sales volumes and are in units of 1000’s. So a value of 2.4 represents 2,400 units sold per week.
So let’s plot that.
untreated = list(set(df.columns).difference({"Denmark"}))
ax = df[untreated].plot(color=[0.7, 0.7, 0.7])
df["Denmark"].plot(color="r", ax=ax)
ax.axvline(treatment_time, color="k", linestyle="--")
ax.set(title="Observed data", ylabel="Sales volume (thousands)");
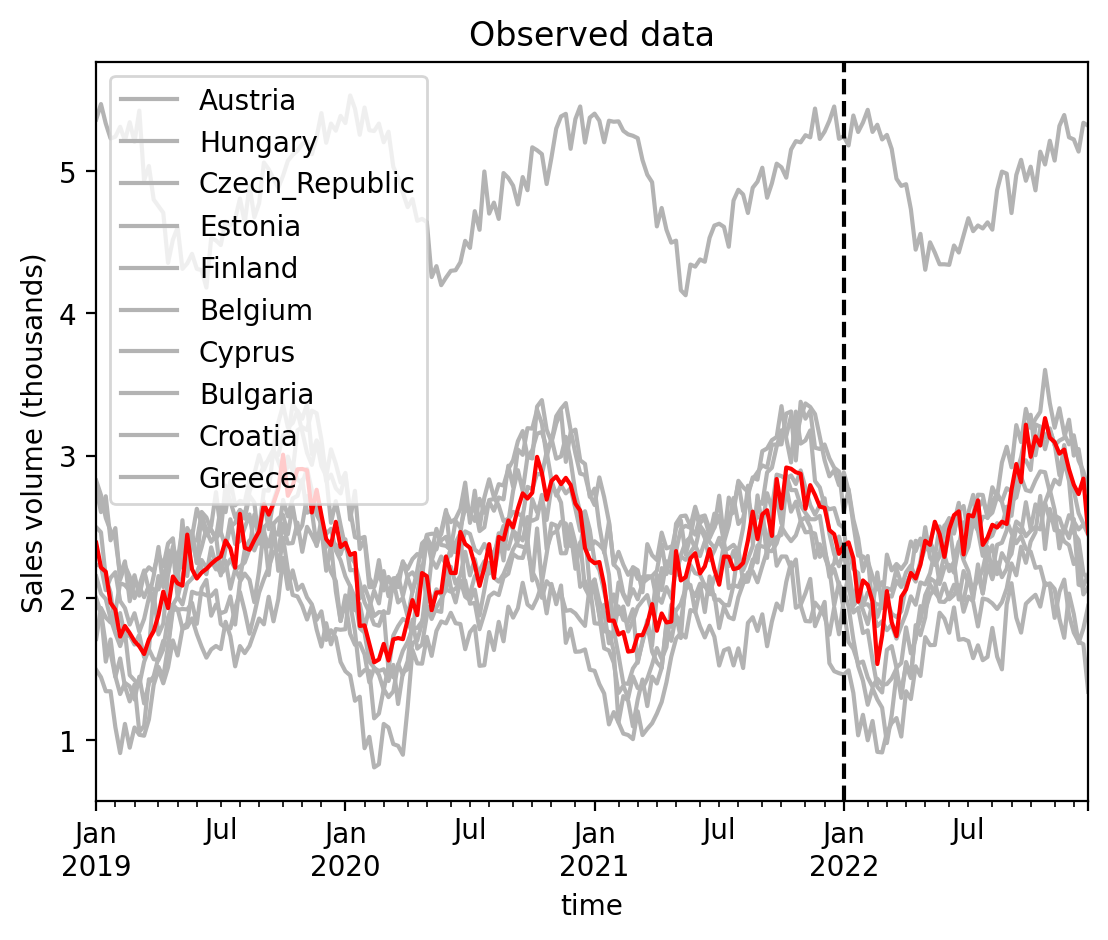
This looks pretty nice, but also disappointing. It is not immediately obvious from a visual inspection that there is a clear change in sales data in Denmark after the stores were refurbished (shown by the dashed line). This is made worse by the presence of annual seasonality in the data (which is different in each country), and the inherent stochasticisty in the weekly sales data.
Pre-experiment diagnostics: market correlations#
Before fitting a model, it is worth checking how similar the candidate control markets are to each other and to the treated market. Markets that move together in the pre-treatment period are more likely to produce a reliable synthetic control – the weighted combination of controls will more easily replicate the treated unit’s trajectory.
CausalPy provides plot_correlations() to visualise the pairwise Pearson correlations between all locations in the panel data. High positive correlations between the treated market and several controls suggest that the control pool can plausibly reconstruct the treated unit’s counterfactual.
pre_treatment = df.loc[df.index < treatment_time]
corr, ax = cp.plot_correlations(pre_treatment)
ax.set(title="Pairwise correlation of pre-treatment sales");
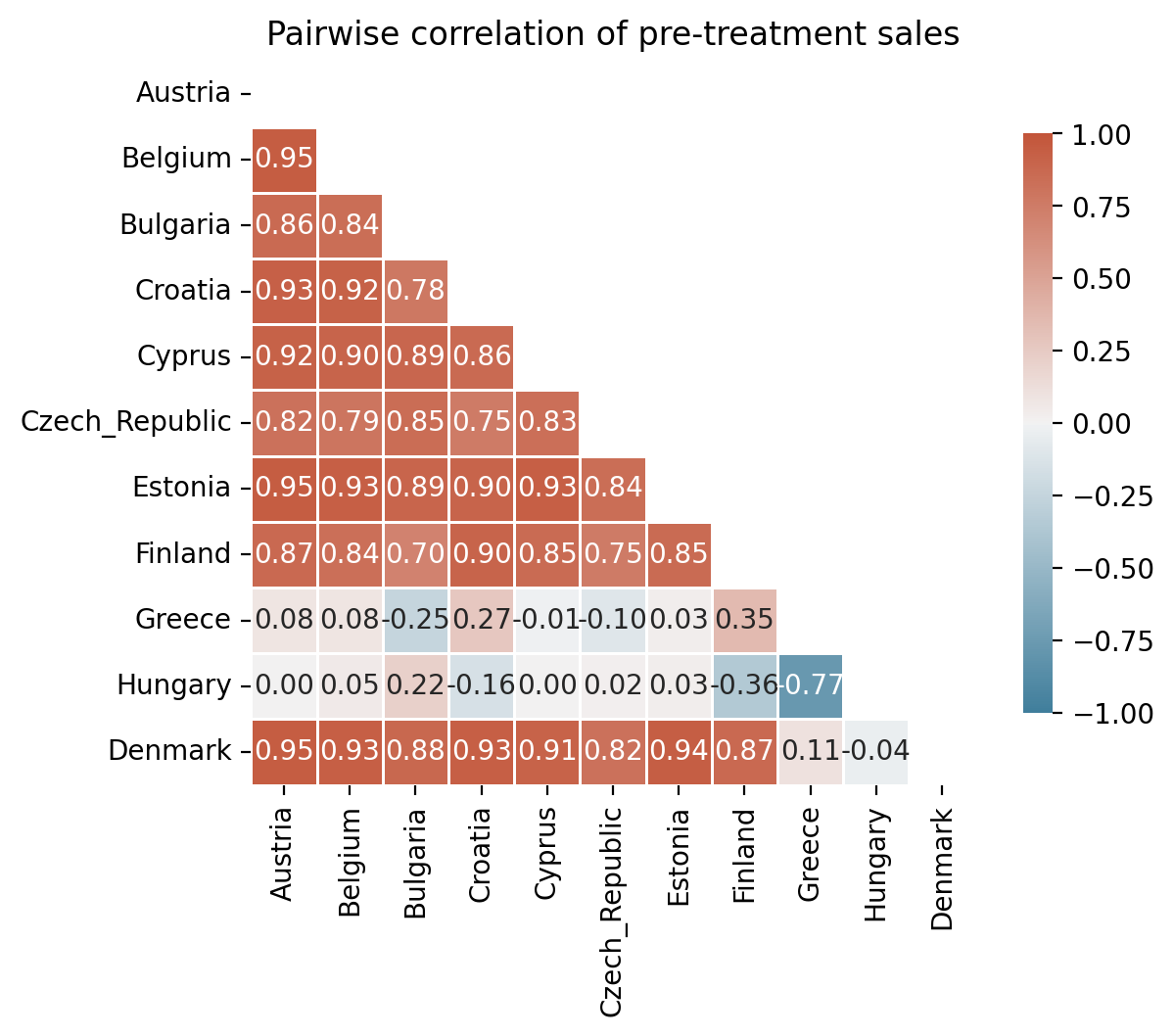
The heatmap reveals that most countries are strongly positively correlated with Denmark, but two countries – Greece and Hungary – are negatively correlated with the treated unit. This is a sign that those markets are driven by different underlying factors and would be poor donors for the synthetic control.
Donor pool selection#
The synthetic control method works by reconstructing the treated unit as a weighted combination of control units. Including controls that move in the opposite direction to the treated unit can introduce interpolation bias and push the synthetic control outside the convex hull condition of the donor pool [Abadie et al., 2010, Abadie, 2021]. Abadie and L'Hour [2021] further show that dissimilar donors amplify estimation error in disaggregated settings.
Practical guideline
Before fitting a synthetic control model, inspect the pre-treatment correlation heatmap and exclude any control units that are negatively correlated (or only weakly correlated) with the treated unit. This is especially important for Bayesian implementations that use a Dirichlet prior, since all donors receive non-zero weight by construction.
denmark_corr = corr["Denmark"].drop("Denmark")
good_donors = list(denmark_corr[denmark_corr > 0].index)
excluded = list(denmark_corr[denmark_corr <= 0].index)
print(f"Keeping {len(good_donors)} donors: {good_donors}")
print(f"Excluding {len(excluded)} units: {excluded}")
Keeping 9 donors: ['Austria', 'Belgium', 'Bulgaria', 'Croatia', 'Cyprus', 'Czech_Republic', 'Estonia', 'Finland', 'Greece']
Excluding 1 units: ['Hungary']
With the contrarian markets removed, the remaining donor pool consists of countries that co-move with Denmark during the pre-treatment period. We can now proceed to fit the synthetic control model using these curated donors.
Was there a geolift in sales in Denmark?#
In order to calculate what (if any) causal effect there is from the store refurbishment we need to compare the actual sales in Denmark after the intervention and the counterfactual sales in Denmark if the intervention had not taken place. We can see why this is called the counterfactual - we did refurbish the stores in Denmark, so this is a completely hypothetical scenario that runs counter to the facts. But if we could measure (or more realistically estimate) this, that would be our control group.
In this case, we generate a synthetic control, which is the name of the technique we will be using to estimate our counterfactual sales data in Denmark if the refurbishment had not taken place. You can read more about the synthetic control method on the synthetic control wikipedia page, but the basic idea is as follows. For those familiar with traditional (non-Bayesian) modelling methods, the basic synthetic control algorithm can be described like this:
import my_custom_scikit_learn_model as weighted_combination
# fit the model to pre-intervention (training) data
weighted_combination.fit(X_train, y_train)
# estimate the counterfactual given post-intervention (test) data
counterfactual = weighted_combination.predict(X_test)
# estimate the causal impact
causal_impact = y_test - counterfactual
# cumulative causal impact
np.cumsum(causal_impact)
So there is no magic involved - we simply estimate a synthetic Denmark as a weighted sum of the untreated units. We do this based on the ‘training’ data observed before the intervention. We then use that weighted sum model to predict our synthetic Denmark based on ‘test’ data of untreated countries observed after the intervention. We can then simply compare this counterfactual estimate with the observed sales data in Denmark and obtain our estimate of the causal impact. We can then (optionally) calculate the cumulative causal impact to answer the question “How many more sales were caused by the store refurbishment over 2022?”
We can use CausalPy’s API to run this procedure, but using Bayesian inference methods as follows:
Note
The random_seed keyword argument for the PyMC sampler is not necessary. We use it here so that the results are reproducible.
result = cp.SyntheticControl(
df,
treatment_time,
treated_units=["Denmark"],
control_units=good_donors,
model=cp.pymc_models.WeightedSumFitter(
sample_kwargs={"target_accept": 0.95, "random_seed": seed}
),
)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta, y_hat_sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 13 seconds.
There was 1 divergence after tuning. Increase `target_accept` or reparameterize.
Sampling: [beta, y_hat, y_hat_sigma]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
We can see that our sampling went well. PyMC returns no sampling warnings, and we have no divergences. If we wanted to take a closer look to diagnose the sampling process we could do the following:
az.summary(result.idata, round_to=2)
az.plot_trace(result.idata, var_names=["~mu"], compact=False);
Results#
Let’s use Arviz examine the posterior parameter estimates for each of the beta weightings for each country, along with the estimate of the measurement standard deviation, sigma.
az.plot_forest(result.idata, var_names=["~mu"], figsize=(8, 3), combined=True);
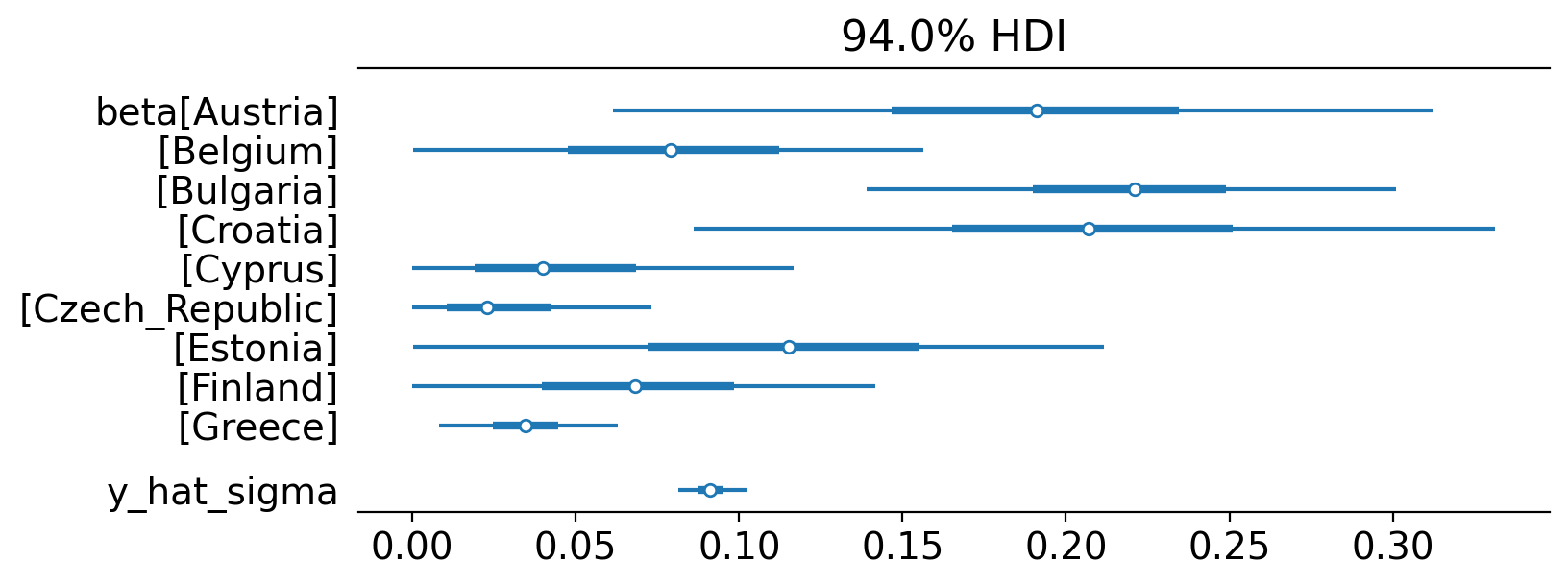
If you are new to Bayesian methods, then I would recommend checking out these resources:
The PyMC website pymc.io, especially the examples page.
There are also a whole bunch of video resources including:
We can now use the plot method of the result object that we get back from CausalPy. This will give us a pretty detailed visual output.
fig, ax = result.plot(plot_predictors=False)
# formatting
for i in [0, 1, 2]:
ax[i].set(ylabel="Sales (thousands)")
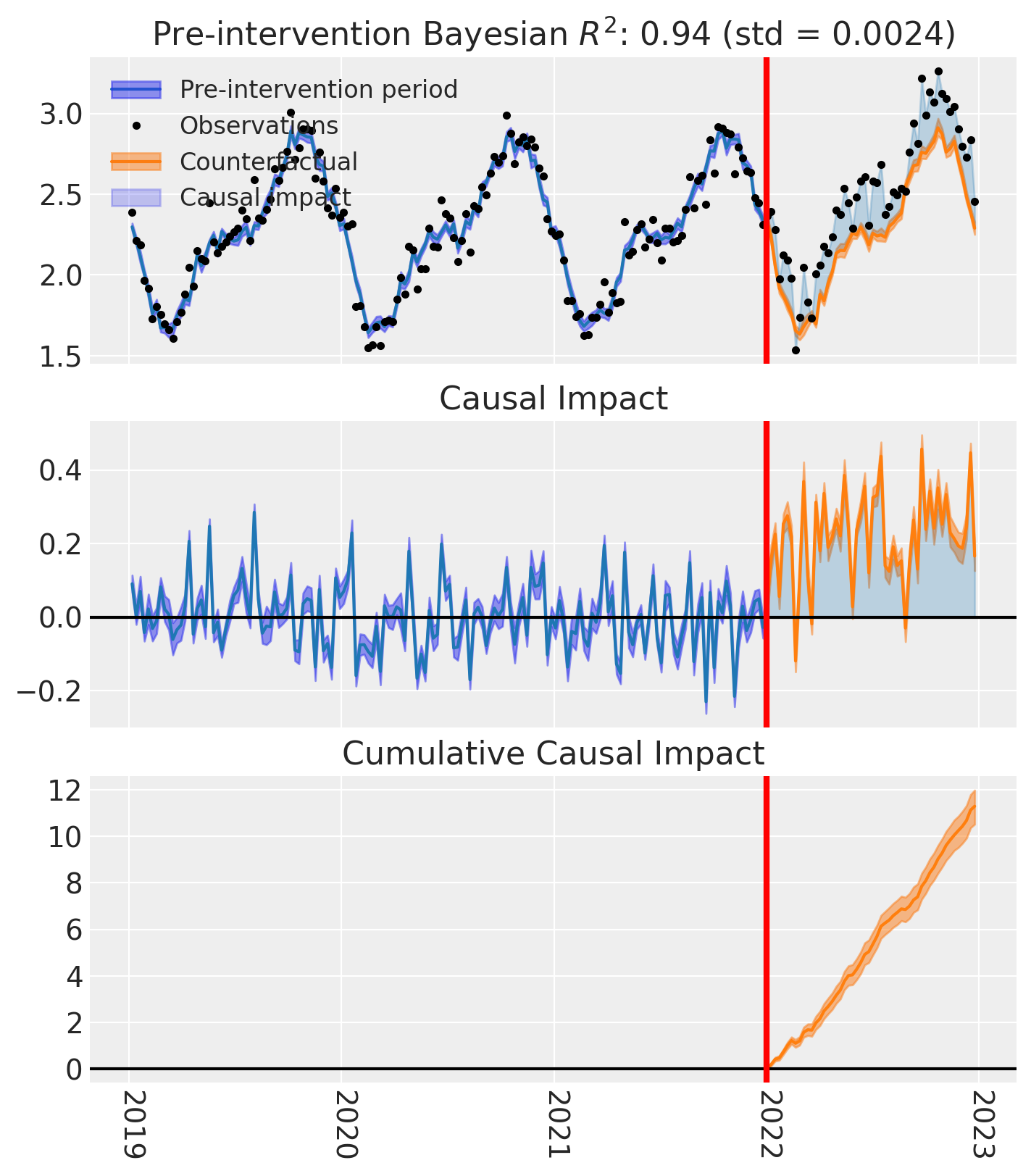
Nice! By creating a simple model formula and one call to CausalPy, we have been able to evaluate the lift generated in the treated unit.
In this example, there is quite a lot of measurement noise, but because we are using Bayesian inference methods here, we have a precise and principled quantification in our uncertainty.
We can see that the Bayesian \(R^2\) value for the pre-treatment data is about 0.5. This is not excellent, but pretty good for real-world data. It shows that the linear weighted combination model (the core of synthetic control) is doing a reasonable job at constructing a faux (i.e. synthetic) Denmark up until the treatment period.
This synthetic control Denmark is our estimated counterfactual - what the sales would have been if the store renovation project had not been carried out. By looking at the difference we can estimate the causal impact, or we could also call it ‘geographical lift’.
Over the year since implementation, we can see that the cumulative causal impact of sales in Denmark was close to 10,000 units. Let’s examine that in more detail. Below we look at the posterior distribution of the cumulative causal impact at the end of our time series, after the scheme had been in place for 1 year.
# get index of the final time point
index = result.post_impact_cumulative.obs_ind.max()
# grab the posterior distribution of the cumulative impact at this final time point
last_cumulative_estimate = result.post_impact_cumulative.sel({"obs_ind": index})
# get summary stats
ax = az.plot_posterior(last_cumulative_estimate, figsize=(8, 4))
ax.set(
title="Estimated cumulative causal impact (at end of 2022)",
xlabel="Sales (thousands)",
);
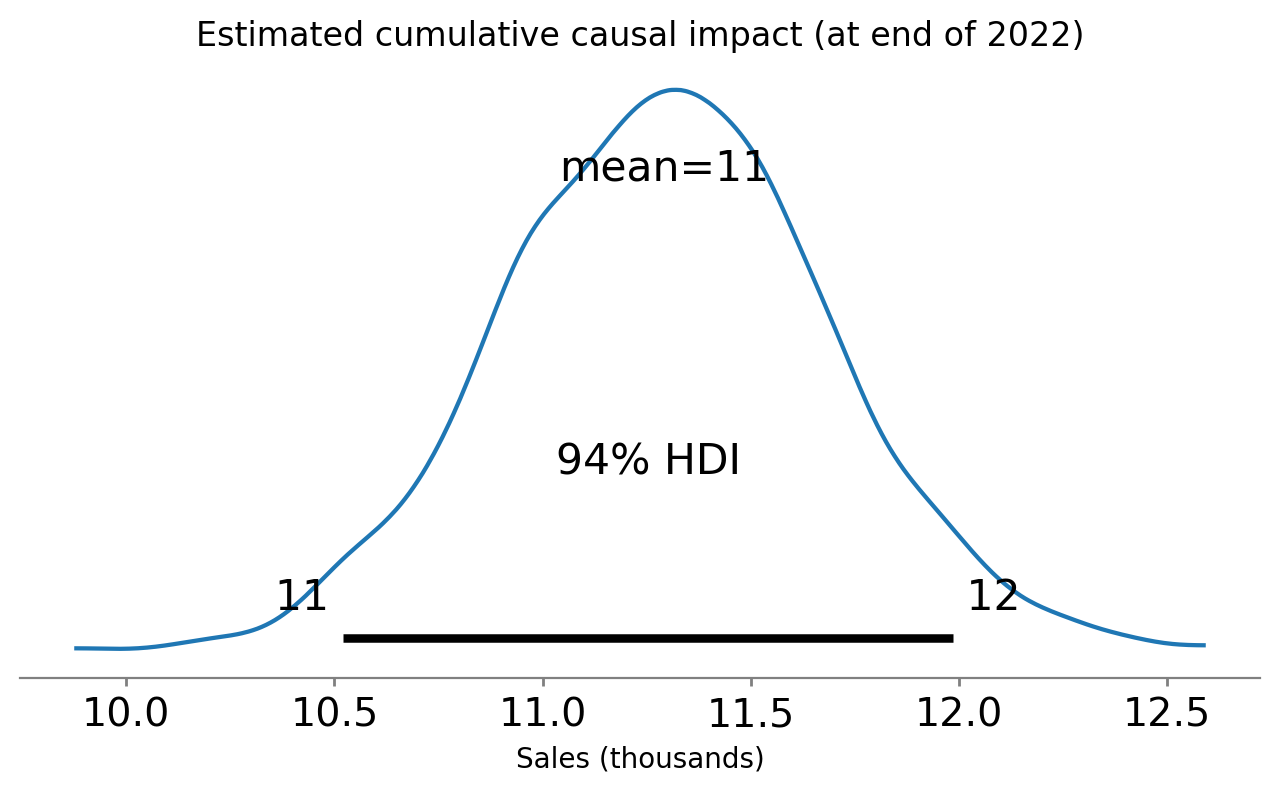
If we want, we can also extract these statistics out numerically:
az.summary(last_cumulative_estimate, kind="stats")
| mean | sd | hdi_3% | hdi_97% | |
|---|---|---|---|---|
| x[Denmark] | 11.29 | 0.39 | 10.52 | 11.99 |
Effect Summary Reporting#
For a decision-ready summary, you can use the effect_summary() method which provides a concise report with average and cumulative effects, HDI intervals, tail probabilities, and relative effects. This provides a comprehensive summary without manual post-processing.
# Generate effect summary for the full post-period
stats = result.effect_summary(treated_unit="Denmark")
stats.table
| mean | median | hdi_lower | hdi_upper | p_gt_0 | relative_mean | relative_hdi_lower | relative_hdi_upper | |
|---|---|---|---|---|---|---|---|---|
| average | 0.22 | 0.22 | 0.2 | 0.23 | 1.0 | 9.55 | 8.81 | 10.22 |
| cumulative | 11.29 | 11.29 | 10.5 | 12.02 | 1.0 | 9.55 | 8.81 | 10.22 |
print(stats.text)
During the Post-period (2022-01-02 00:00:00 to 2022-12-25 00:00:00), the response variable had an average value of approx. 2.49. By contrast, in the absence of an intervention, we would have expected an average response of 2.27. The 95% interval of this counterfactual prediction is [2.26, 2.29]. Subtracting this prediction from the observed response yields an estimate of the causal effect the intervention had on the response variable. This effect is 0.22 with a 95% interval of [0.20, 0.23].
Summing up the individual data points during the Post-period, the response variable had an overall value of 129.59. By contrast, had the intervention not taken place, we would have expected a sum of 118.30. The 95% interval of this prediction is [117.57, 119.09].
The 95% HDI of the effect [0.20, 0.23] does not include zero. The posterior probability of an increase is 1.000. Relative to the counterfactual, the effect represents a 9.55% change (95% HDI [8.81%, 10.22%]).
This analysis assumes that the control units used to construct the synthetic counterfactual were not themselves affected by the intervention, and that the pre-treatment relationship between control and treated units remains stable throughout the post-treatment period. We recommend inspecting model fit, examining pre-intervention trends, and conducting sensitivity analyses (e.g., placebo tests) to support any causal conclusions drawn from this analysis.
So at the end of our causal modelling endeavours we can report to our boss something along the lines of: “We believe that the store refurbishment scheme was causally responsible for driving a total of about 9150 additional sales. But we have uncertainty in the exact number of additional sales - our 94% credible regions span 7,420 to 10,790”.
There are of course caveats worth bearing in mind. The analysis we’ve conducted has assumed that the only major event that might selectively influence sales in Denmark was the store renovation project. If this is a reasonable assumption then we may be on relatively stable ground in making causal claims. But if there were other events which selectively effected some units (countries) and not others, then we may need to be much more cautious in our claims and resort to more in-depth modelling approaches.
But our estimated cumulative causal impact of \(9150^{7420}_{10790}\) is exactly the information needed by others in the company. They can use this figure (and even the uncertainty associated with it) and estimate how long it would take for the cost of renovating other stores to result in a net profit.
Your boss is very happy. You get a big end-of-year bonus.
Beyond GeoLift#
This example used geographical regions as the treatment units, but there is no requirement for units to be geographical regions. For example, your units could be products. Maybe your company sells many different products and one (or a few of these) are chosen to be discounted. Did this intervention of discounting the price causally increase sales volumes? Synthetic control methods can answer this (and similar questions) just as easily.
We can get nicely formatted tables from our integration with the maketables package.
from maketables import ETable
ETable(result, coef_fmt="b:.3f")
| y | |
|---|---|
| (1) | |
| coef | |
| Austria | 0.191 |
| Belgium | 0.082 |
| Bulgaria | 0.219 |
| Croatia | 0.208 |
| Cyprus | 0.048 |
| Czech_Republic | 0.029 |
| Estonia | 0.116 |
| Finland | 0.072 |
| Greece | 0.035 |
| stats | |
| N | 208 |
| Bayesian R2 | 0.94 |
| Format of coefficient cell: Coefficient | |